The Web today is about a 15,000 volume library, but it is missing many key works. Ian Irvine, chairman of Reed Elsevier, says that his journals reject 80% of what is submitted, and that this rejected material is what is available free on the Web. Why do we not have the published journals available online? Primarily for lack of a safe way to charge. Publishers are reluctant to place valuable intellectual property on the Web, fearing that people will redistribute it without permission.
Some kinds of online information distribution are working well, and online information is a booming industry today. The information retrieval industry grossed $13.5 billion in 1993, with a 25% growth rate in online subscribers and a 44% growth rate in home subscribers. The industry is responsible for 45,000 jobs in the United States. The information files available are enormous: Mead Data Central, for example, had 2.4 terabytes of online information in early 1994. Of all the electronic information for sale, 2/3 is online, 12% is CD-ROM, and the rest is audiotext, magnetic tape, and other media. [ed. 1994]. Much online information is financial, but the largest online vendors of text are shown in Table 1.
| Table 1: Online Vendors (1993) | |
|---|---|
| Mead Data Central | $550M |
| Dialog | 243M |
| Prodigy | 223M |
| Westlaw | 210M |
| Compuserve | 177M |
| Dow Jones | 83M |
| Genie | 43M |
| AOL | 40M |
| BRS/Orbit | 36M |
| Data Broadcasting | 29M |
| Info America | 25M |
| Delphi | 11M |
| Table 2:1994 CD-ROM sales | ||||
|---|---|---|---|---|
| K-Units | M-Dollars | |||
| Sales | Growth | Sales | Growth | |
| Home Education | 6,238 | 258% | $106.6 | 229% |
| Content | 6,279 | 143% | 156.0 | 109% |
| Games/Oth. Home | 7,551 | 222% | 169.2 | 275% |
| Languages & Tools | 490 | 182% | 102.6 | 434% |
| Other Products | 2,231 | 191% | 113.1 | 348%
|
| Totals | 22,790 | 199% | $647.5 | 229% |
The United States dominates this industry. Table 3 shows the balance of payments in information services. [BEA 1995].
| Table 3: Balance of Payments |
|---|
| 1994 |
| Whole world |
| EU |
| Japan |
Sales of information on the Web are also growing rapidly. ActivMedia estimates that sales on the Web will grow from $436M in 1995 to $46B by 1998. 43% of Web sales are exports. The largest category of sales is airline tickets, but the computer vendor NECX Direct says it is doing over $1M/month. Advertisers spent $33M on Web advertising in the first six months of 1995, and Forrester estimates that in 2000 advertising will be $2.6B on the Web.
For sales information, advertiser support is fine, as is support for some very popular pages. Yahoo charges $20,000 per month, and HotWired $30,000 for 8 weeks. At the other extreme American Horsemen On Line charges $40/month. Most scholarly journals and textbooks, however, have not historically received much advertising, and it is not expected that their online versions could be advertiser-supported, either. To get scholarly digital information online, we shall need either author support or reader support.
Author support has been suggested by a number of people, including Steve Harnad [Okerson 1994]. and Andrew Oldyzko, [Odlyzko 1995]. who have argued that costs of online publication will be so low that we can expect free distribution, in which the author pays all costs. For much material, however, we would expect that readers or reader institutions would be asked to contribute, since today there are still not enough author institutions prepared to shoulder enough editorial costs to provide high-quality online material. Transfer of traditional publishing to electronic distribution may lower some costs, but the existing structure may remain in place.
Digital libraries, then, will wish to piggyback on the methodologies used by publishers. Whatever technologies are used to provide textbooks, journals, and other valuable information to students and scholars, we can expect libraries to be able to take advantage of those technologies as well. The commercial industry is growing rapidly and has spread from access by traditional librarians to access by individuals. The number of Internet and online users, for example, is estimated to have gone from 6 million in 1994 to 9 million in 1995 and is expected to be 15 million in 1996 and 22-25 million in 1997. [Parekh 1995]. Libraries can expect to use the same methods to distribute their material, and in fact publishers may find that the easiest way to maintain a backlist is to license the libraries to distribute their copies, paying some kind of fee per reprinting or other transmission.
Publishers are often afraid of providing online information for fear that it will be stolen and reused. They hear computer scientists give talks with phrases like ``the nationwide file system'' and they fear that this means that everyone in the country, or perhaps the world, will be able to access one electronic copy of their material; thus the first sale will be the only one. They remember the collapse of the computer game market in the early 1980s due to illegal copying, and are aware of the software piracy problems in many countries. The Software Publisher's Association estimates that piracy costs the software industry $15B per year. [Corcoran 1995]. In some countries, such as Thailand and Pakistan, more than 95% of the copies of software in use are illegally made, with almost no legal copies around. Worse yet, some places (most notably China) are re-exporting illegal copies, cutting into the software market in places (such as Hong Kong) which had made great progress at eliminating locally made illegal copies. Book publishers are afraid of the same thing happening to them, and are looking for a technological fix that would prevent people from pirating intellectual property.
Traditionally, the large databases have avoided the worst of these problems by their method of operation, giving out only small parts of the database at a time. Users of a system like NEXIS or Dialog may well be able to capture a screenfull of output, representing a single article or abstract; but they are not likely to be able to find somebody else who wants that particular item and is willing to pay for it. Thus, piracy of such a system (which provides only the tiniest fraction of its content on each interaction) is not an insuperable problem. Book publishers, however, who would like to deliver an entire book online, do not feel that same confidence. They know that an undergraduate who has purchased the right to a textbook for one of his classes, for example, has easy access to his fellow students who also need the same textbook, and they fear unauthorized duplication. Current statistics on library theft, for example, would not reassure them as to the honesty of current undergraduates.
The techniques of ``digital watermarking'' or ``steganography'' are often recommended to deal with this problem. These methods involve the concealment within a digital object of a special code, which does not interfere with reading or viewing the object, but which can be used to track copies. [Komatsu 1990]. The idea is that each copy sold would be labeled with a different identification number, and illegal copies could thus be tracked back to the original purchaser so that legal remedies could be sought against that purchaser. These codes have the difficulty that they may be easily removed, and they may be hard to insert. It is easier, for example, to find spare places to put extra bits in a picture (where low-order detail can be adjusted with little notice) than in text. [Matsui 1994]. And even if the proposed law against protection-breaking software passes, it is going to be hard to outlaw low-pass spatial Fourier transforms, which would attack many of the proposed picture labeling schemes.
The most serious difficulty with digital watermarking for those who wish to display text is that it is particularly hard to find a way to put such codes in Ascii text. For this reason there have been suggestions that publishers wishing to send ordinary text should code it as bitmaps and send those despite their greater bulk. [Lesk 1993]. Perhaps the most imaginative solution is that of J. T. Brassil et al. at Bell Laboratories, in which they used such techniques as adjusting the space between letters and words in Postscript to hide extra codes. If the user indeed copies the exact image of the page, this will permit tracking of the copy. [Brassil 1994].
Digital watermarking also does not actually prevent copying; it merely makes it possible to track the source of an illegal copy back to the first purchaser. However, since the Business Software Alliance [Lohr 1995]. estimates that 90% of illegal software use in the United States is unorganized and individual, legal action against the copiers may well be expensive and unrewarding. It is for this reason, of course, that the proposed White Paper on Intellectual Property and the NII suggests that online service providers be responsible for policing copyright violation, but it remains to be seen whether this will be enacted. For the moment legal techniques are expensive when used against a myriad of individuals many of whom may have small financial resources.
Another technique used in the software industry to control illegal use of software is the ``dongle,'' a special-purpose hardware device that must be present on the machine involved for the software to work. Encyclopedia Brittanica, for example, uses such a device to protect its content. These devices are relatively cheap and prevent software from run on a different processor. These devices meet some consumer resistance since they prevent someone from moving their work quickly from one machine to another (as is of course their intent) and also just seem to be a higher level of hassle than with other software.
Although transmitting bitmaps and controlling the software and or hardware that is used to display them helps prevent people from copying the material they access, this is not a complete solution. The user can always just take a screen dump, capture the bits off the screen, and run them through an OCR program. The publisher will then be thrown back on legal remedies for copyright violation.
Is there a way to let people see something and read it, but not capture it by screen dumping? This would seem contradictory, but this paper proposes a solution, relying on the ability of the human eye to average rapidly changing images. As is known from movies and television respectively, if the eye is presented with images changing 24 or 30 times per second, it tries to average the result, rather than perceive the separately changing images (as it would if the images changed every second or every two seconds). Computer screen dumps, on the other hand, capture an instantaneous appearance. They don't do any time averaging over the screen appearance.
Thus, imagine that we take a text to be displayed, and add random bits to the background. Suppose we do this twice, so that we have bitmaps which contain all the bits in the letters, plus perhaps 50% of the remaining bits, at random, turned on. Then we rapidly alternate between these bitmaps. The human eye will perceive the steady letters as letters; it will take the irregular flickering bits in the background as equivalent to a 50% grey background. After all, this is what we would do if we wished to use dithering to represent a 50% grey rectangle. So the eye will perceive steady letters on a grey background. Any screen dump, however, will capture the enormous amount of background bits as garbage, and the resulting screen image is almost useless.
Figure 2 shows this process. The top two bitmaps, if merged together, produce the appearance of the lower image (the text is from the Prolog to Henry V). In a static paper, it is not possible to show the flickering, so the lower image is 100% black letters on a flat 50% grey background. However, if read on a screen with about 30 repeats per second, this is roughly the appearance that results. An even higher flicker rate would be desirable; rates as low as 15 repeats per second cause the changing background to appear as an annoying Moire-like pattern, rather than as a steady grey level. The separated bitmaps, although barely readable by the human eye, have been tried on OCR programs, with no useful output. The eye is of course much better than an OCR program at deciding what represents a possible letter and what is random noise.
The density of the background can be adjusted. Clearly, moving to a lighter background (fewer dark bits) produces a more readable image, at the expense of making it easier to imagine an OCR program that can deal with the separated bitmaps. Tests suggest, however, that even 10-20% of random bits added to a bitmap will make OCR ineffective. Note, however, that this assumes a normal letter size; if the letters are greatly enlarged relative to the dots, the noise is easier to remove.

Figure 2: Flickering text. Alternating the top two images produces the impression of the bottom image.
This has been implemented using a Unix X-windows program that starts with a bitmap of letters, exactly as they would normally be put on the screen. These can be made easily enough from text using any typesetting-type program. For each bitmap to be displayed, two random bitmaps with grey density 25% are made. That is, one bit in each 4 is dark (all bits are either black or white). These bitmaps are then ``ored'' with the text bitmap, so that there are two bitmaps each of which contains the original text plus 25% of the white space cluttered up with more dark bits. The program then switches quickly between the two bitmaps. The text bits are in both examples, so the eye sees those bits constantly. The changing and irregular dark bits from the random grey bitmaps are averaged by the eye into a grey background, so that instead of seeing clean black on white the eye sees black on grey. The grey background is changing constantly
and thus somewhat annoying, but you can read the text clearly. If you screen dump the window, you get one of the two bitmaps with the cluttered data. With a 25% dark bit density level these can only be read with some annoyance by the human eye, and certainly not by an OCR program. Figure 3 shows the result of this process.
There are various choices in this system. The random bitmaps can have any grey level. In particular, if the background grey level is about 10% you get a very easy to read onscreen display, but a reader can make out the cluttered images when isolated easily as well (but I still find that OCR programs fail). If the background level is 50%, the display is now a fairly dark background but still quite readable when flickered. The individual cluttered images are then not even easily recognizable as text by eye, let alone readable.

Figure 3: Less background
Another choice is to have the background flat white, and flicker between two images of the text, each of which has half the bits from the letters. This produces a different impression: instead of seeing good letters against a flickering grey background, you see flickering letters against a clean background. The half-images are recognizable as text but not easy to read (and again won't make it through OCR). This form, with flickering letters, seems a little harder to read than the steady-letter, flickering-background form (and it is easier to imagine how it might be attacked with bit-cleanup techniques). See Figure 4.
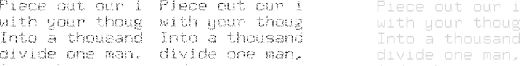
Figure 4: Flicker text, not background
Note that it may not be desirable to have too many background bitmaps. If a method of attack is to capture both images and try to logically ``and'' them to uncover the letters, the more random backgrounds that are used, the more likely it is that the letters will be apparent. It is also possible to combine the idea of flickering backgrounds and flickering letters, with perhaps a 25% background and a 75% letter density.
Another feature is to ``wobble'' the text up and down the screen slowly. This doesn't bother the reader as much as the flickering, and it defeats a user who might say ``I can defeat this program by setting up something which will just make 100 screen dumps in succession and then average the result.'' With the text wandering up and down the screen, the averaging will be destroyed.
In designing the use of this algorithm, we assume that the more obvious steps in copyright protection will be taken. For example, the text to be read should be transmitted in encrypted form to the user's machine, so that ``packet-sniffers'' recording the content of the packets moving to the machine won't get anything useful. The user must employ a utility written by the information provider to display the file, which encorporates the decryption step, so that the decrypted text is not written anywhere on a file in the user's machine. The actual display should be managed as a bitmap, which can be done with a JAVA program.
This technology does not work as well with displays of pictures rather than text. Without the familiar letter-shapes to guide the eye, the addition of noise to a photograph of a real scene makes it considerably noisier, rather than being an apparent ``background.'' However, the digital watermarking techniques are applicable exactly to such pictorial images. Thus, the flickering technique is applicable exactly when the watermarking techniques are not, and fills an important slot in copyright defense technology.
Difficulties with this technology include the inability of current technology to flicker quite fast enough, or to display small enough dots. On a Sparc 10, we see maximum rates of about 30 images per second running with C code for X-windows; we would like to double that. Running under JAVA, the flicker rate ranges about 20-40 images/second (even on windows about 600x100). In addition, each dot on a modern screen is still large enough to be easily perceived; we would like smaller dots, so that they blend more easily. With time, both of these difficulties should be swept away by increasing hardware capability.
An example of the kind of interface that is possible is shown in Figure 5. Using Java, the program fetches files from a server machine and displays them on the client machine. There are four levels of security which the interface can mimic; for demonstration purposes these are button-selected, but in reality the intellectual property owner would stipulate the degree of protection required.
Under ``none'' a file is simply displayed and the only security is that there is no ``save'' button, and that moving the mouse out of the viewing window blanks the window (except for a message to put the mouse back in the window). This keeps only an extremely naive user from screen dumping the file. The ``low'' button, as shown in Figure 5, presents an encrypted form of the text (not very secure encryption in this example) and asks for a password. On typing the correct password the file will be presented in cleartext form.
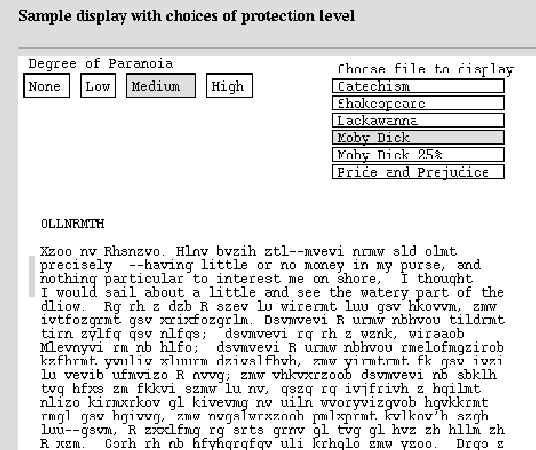
Figure 5: Java interface
If desired for additional restrictions, the passwords could be one-time use or otherwise limited in their capabilities, or the image could go away after some number of seconds. ``Medium'' security involves only displaying a portion of the file at a time. The mouse must be moved up and down, in this case (as shown in Figure 4) always keeping only three lines decoded. With such an interface, screen dumping is a pain since the user would have to manually clip out the correct lines from each dump (the marking of the cleartext lines is for the benefit of this viewgraph, and would not be in the final program). Finally, the ``high security'' version is the flickering version, shown in Figure 6, whose screen dump is unreadable. That's the point of this interface; you can't make a readable screen dump. It's what it does.
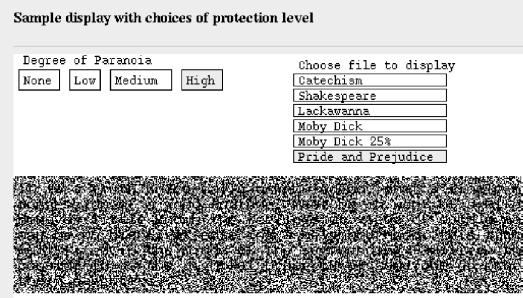
Figure 6: Java interface to flickering
This technology, of course, keeps users from doing many of the operations they would like to do, such as cut-and-paste or 'egrep' searches on the files. Of course, it is the intent of this software to make these impossible without the copyright holder's permission; but it may be best if the user interface supports the operations which are not a threat to the copyright holder. For example, saving small quantities of information, or doing searches, should be allowed by the interface, and controlled as to quantity to prevent risk.
Some attention must be paid to the grey background density compared with the size of the letters. The larger the letters are compared with the background and the fainter the apparent background, the more readable the separated images are going to be. That is, for an image in which the letters are a normal screen size, adding 25% random bits may make it unreadable; where as even 50% random bits may not render an image which is 8X normal size illegible. In short, it is not desirable in this system to let readers scale the images as large as they want; it increases the chance that simply cleaning up all isolated dots will leave a clean set of letter images behind.
This technology makes it possible for copyright owners to display works to users but not let them download. By doing so, it should enable additional kinds of material to be safely offered on online services.
[BEA 1995]. Bureau of Economic Analysis National Trade Data Base U. S. Department of Commerce (1995).
[Brassil 1994]. J. T. Brassil, S. Low, N. Maxemchuk, and L. O'Gorman; "Marking of Document Images with Codewords to Deter Illicit Dissemination," Proc. INFOCOM 94 Conference on Computer Communications pp. 1278-87 (1994).
[Corcoran 1995]. Elizabeth Corcoran; "In Hot Pursuit of Software Pirates," Washington Post pp. F01 (August 23, 1995).
[Komatsu 1990]. N. Komatsu, and H. Tominaga; "A proposal on digital watermark in document image communication and its application to realizing a signature," Electronics and Communications in Japan, Part 1 (Communications) 73 (5) pp. 22-23 (1990).
[Lesk 1993]. M. Lesk; "How can digital information be protected," Research Challenges in the Economics of Information, CNRS, Poigny-le-Foret, France (July 1993).
[Lohr 1995]. Steve Lohr; "Pirates Are Circling The Good Ship Windows 95," New York Times pp. D6 (August 24, 1995).
[Matsui 1994]. K. Matsui, and K. Tanaka; "Video-Steganography: How to Secretly Embed a Signature in a Picture," Technological Strategies for Protecting Intellectual Property in the Networked Multimedia Environment 1 (1) pp. 187-206 (Jan. 1994).
[Odlyzko 1995]. Andrew Odlyzko; "Tragic Loss or Good Riddance: The impending demise of traditional scholarly journals," International Journal of Human-Computer Studies 42 (1) pp. 71-122 (1995).
[Okerson 1994]. A. Okerson, and J. O'Donnell Scholarly Journals at the Crossroads: A Subversive Proposal for Electronic Publishing Association of Research Libraries (1994). Also available directly on the Web as: http://cogsci.ecs.soton.ac.uk/~harnad/subvert.html.
[Parekh 1995]. Michael Parekh; "Byways to Highways: Investment Opportunities in CyberCommerce," CyberCommerce Conference, First Annual Goldman Sachs Intenet Conference, Phoenix, Arizona (1995).
[Rodriguez 1995]. Karen Rodriguez; "Searching the Internet," Interactive Age pp. 28-30 (July 31, 1995).
[ed. 1994]. Kevin Hillstrom, ed. The Encyclopedia of American Industries, vol. 2 Gale Research (1994).