
Digital libraries are needed both to let libraries offer new and improved services, and to deal with a cost crisis now affecting their current services. Dreams of computer-based libraries, which have been around for decades, [Bush 1945] are now practical. There are libraries (e.g. in some pharmaceutical companies) which already spend more than half their acquisitions budget on electronic resources, rather than paper. Meanwhile, many university libraries are finding it impossible to maintain their traditional collecting practices within the constraints of their institutional budgets. They look eagerly to the new technology as a solution.
The current scholarly publishing system is breaking down. Libraries can afford an ever decreasing fraction of the world's publications. The Mellon Foundation has prepared studies showing that between 1970 and 2000 the typical US academic research library will lose nearly all its purchasing power [Cummings 1992]. Increases in journal and monograph prices, currency shifts, and increases in the number of publications are all making it harder for libraries to afford their previous level of purchases. Nearly every university is reviewing its subscriptions and canceling journals. The whole system is near collapse.
Since much of the cost of printing many scholarly journals is pre-press (editorial, composition, make-ready, and so on) a loss of subscriptions means that the cost to the remaining subscribers must be increased. This will cause still more price increases and then cause additional libraries to stop purchasing those journals. The result has been a globally strange optimization: despite the large economy of scale in printing journals, libraries work out sharing arrangements because they can not afford to buy more copies. This is counter-productive, since it leads to still fewer subscriptions and still higher prices, but there is nothing one library can do about the situation. It is a problem independent of technology; exactly the same situation is observed with CD-ROMs, with libraries working out ways to provide network access, when CD-ROMs again are a technology with huge economies of scale and low incremental costs (designed to stamp out millions of pop records, the incremental cost of producing another CD-ROM is in the range of $2) but produced for libraries in small runs.
In addition to problems buying material, libraries are beset with increasing costs for buildings and storage, and with a steadily growing problem of acid paper books which are deterioriating and need treatment. Something over 100 million books in the United States are brittle, and there is as yet no suitable solution (photocopying and deacidification are both too expensive, and microfilm is disliked by many users). Building costs also increase steadily, and on many campuses there is simply no room to put another large library even if the funds are available to build it. Since most universities do not monetize space, this rarely appears in a library budget, but the cost of space is probably comparable to the cost of materials in some realistic accounting.
Thus, libraries are faced with two simultaneous problems: their inability to buy enough new materials, and their inability to keep enough old materials. Electronics can, in principle, be an answer to both. The next figure shows the rough economics of the university library.
At the other end, electronics can be a reasonable solution to the problem of deteriorating books. The Cornell CLASS project found that a 19th century deteriorating book could be scanned for approximately $30-40, even though each page had to be handled separately [Kenney 1992]. Considerably lower costs should be possible for books whose paper is still in better shape. This is beginning to be a cost in the same range as that of on-campus libraries. Recent costs for university library storage, per book, are rising. It is still possible to have cheap warehouse space off-campus; Harvard now puts many books in a Depository, about 35 miles from the campus, at a construction cost of about $2/book. But Cornell has completed one library addition on its campus and is building another, at a cost of about $20 per book in each case. Berkeley is building an underground stack (which must be built to withstand earthquakes) at about $30/book. UCSF, which must deal with both earthquakes and a complex building site, is spending $60 per book (admittedly not for a pure stack). And all of these costs pale in comparison with the new national libraries in London and Paris, both far more expensive than scanning all their books.

The cost of the disk space to store the scanned books would be in the neighborhood of $10 per book. Thus, it is true today that if three or four university libraries, all planning to build a new stack building on campus, and all sharing some 100,000 out of copyright books, could agree to scan these books and share the images, they would be financially better off. In fact, the Mellon Foundation is funding just such a project today at the University of Michigan, in which ten major economics and history journals will be scanned back to issue one. Among reasons more such projects are not underway are (a) many universities do not monetize space, so that a library can not easily convert the cost of a building into the cost of technology; (b) many libraries fear that people will not like computer access to the books, and (c) some libraries lack the technology to access the images if they were available.
So far, digitisation has been described as something that avoids problems. In addition, electronics can offer many advantages to libraries. These include both better access to traditional materials, easier preservation, and extension of library collections.
As many have discovered, the ability to search provides an enormous advantage to electronic materials when an Ascii version is available. Online searching has for some years been replacing printed abstract journals, and we now see in such publications as the Chadwyck-Healey English Poetry Database the use of electronics for full-text humanities material. Although older material is often available only in image format, since essentially all modern material is now printed via computers, it can generally be provided in Ascii form and be searched. For those documents which are searched rather than read \- many reference books, compilations, etc. \- electronics can be expected to take over shortly. Printed encyclopedias in the United States, for example, are giving way to CD-ROMs which are smaller, cheaper, and far more effective to use.
Electronics also provides several other advantages. Ubiquity is one clear edge: a single electronic copy can be accessed from a great many locations, and to many simultaneous users (assuming copyright permission is available). Copies can be delivered with electronic speed, and it may be possible to reformat the material to the convenience of the reader (e.g. in larger type size for those with limited sight, or in order to fit a smaller screen). Since readers get a screen display of the object, rather than carrying away the physical object, loss rates by theft may be much reduced (some CD-ROM systems, however, are vulnerable to theft of this sort). Unfortunately, although the library may be immune from losing access to its own copy via theft, in the digital world there is a different kind of theft in which the copyright holder loses control, rather than the library losing its copy. This will be discussed later.
Another important advantage is preservation. Digital information can be copied without error. As a result, preservation in a digital world does not depend on having a permanent object and keeping it under guard, but on the ability to make multiple copies, assuming that at least one will survive. The major risk to digital objects is usually not physical deterioration but technological obsolesence of the devices to read them. Helical-scan magnetic tape is perhaps the only format likely to wear out before it becomes obsolete. The lifetime of magneto-optical cartridges, linear magnetic tape, and certainly CD-ROM is expected to be in decades, while the lifetime of the reading devices is perhaps only about one decade (except for CD-ROM). But assuming a reasonable refreshing schedule, and a reasonable attempt to avoid buying devices which are special-purpose rather than widely marketed, libraries can expect that digital information will be kept with less deterioration than paper.
The major worry is the funding for the regular refreshing. Libraries today often view preservation as a capital expense; a book is rebound or photocopied and then replaced on the shelf and forgotten. Digital preservation will be an ongoing operation, requiring a regular future expense. Librarians worry that they are committing their successors to operations for which there will be no funds. However, note that every few years the capacities of storage devices get larger and larger. This year the magnetic disk industry will ship 15 petabytes, or 2 MB per person alive in the world. It was only twenty years ago that I remember being hassled to get my disk usage down to 200 KB. As these storage devices get larger, the cost of copying bytes decreases. As a result, if a library can understand how it will fund the first refresh cycle in five to ten years, it can expect that the next refresh cycle will be so cheap as to be insignificant.
A more serious refreshing problem, in reality, is software obsolescence. Milton Halem of NASA has pointed out that the variety of software formats far exceeds the number of hardware devices manufactured, and that these programs come and go more quickly than the hardware does. Libraries should rely on standards \- MARC, SGML, and others \- for which software can be expected to exist into the indefinite future.
Digital storage also permits libraries to expand the range of material they can provide to their users. For example, both audio cassette tapes and vinyl records pose problems to libraries; neither will stand a large number of playings without deterioration. Digitizing the sound can produce a format (the audio CD) that is much safer to use. Digital material can also permit access to fragile photographs, someday to video tapes, and to the new kinds of multimedia materials that are created only on computers and simply have no equivalent in any traditional format.
Some materials in digital libraries are available as images, and others as Ascii. In some cases these distinctions are inherent \- a photograph collection is always going to be images, and an online catalog is nearly always Ascii. In other cases, particularly traditional printed books and journals, both formats are possible. The CORE project, a joint effort of the American Chemical Society, Chemical Abstracts Service, Cornell, Bellcore, and OCLC addressed the choice of these formats.
These issues and experiments will only be discussed briefly, having been presented elsewhere at greater length [Lesk 1994a, 1994b, Egan 1991]. In the CORE project, approximately 300,000 pages of chemistry journals were provided online at Cornell in both image and Ascii format.

In practice, today there is a separation between publisher-generated material and community-generated material. Many publishers are providing images on CD-ROMs, for a fee (e.g. the UMI disks of IEEE publications and many similar ones) while the community material is provided as Ascii, on online bulletin boards, and for free (e.g. the High Energy Physics Preprint system). These boundaries are not sharp \- many full text newspapers are available online in Ascii from publishers, for example, and Cornell has a project to provide CD-ROM images of agricultural literature journals. Despite the widespread view that online will eventually win over CD-ROM and Ascii over image, right now the CD-ROM image format material is growing faster than the online formats in the marketplace (while the online World Wide Web grows faster than anything else) [Odlyzko 1994; Berners-Lee 1992]. Libraries, at least for a while, must be prepared to deal in both worlds.
Images, of course, consume far more space than Ascii files do. A typical page in image format is perhaps 30K bytes, whereas in Ascii it would be a tenth of that.

Given these comments, why bother with images at all? The major reason is financial: the cost of keying a book with 300 pages and 500 000 characters is about $500, ten times the cost of scanning. Other reasons are the simplicity of handling the illustrations or tables on the pages, and the familiar display for the user. However, we can expect that as OCR gets better, the image formats will start to disappear. 4. Some efforts in the United States
Fortunately, a recent issue of \ommunications of the ACM was devoted to digital libraries and reviewed a number of the major projects. There are six projects funded by the combination of NSF, NASA and ARPA as part of their Digital Library Initiative [Christel 1995; Garcia-Molina 1995; Wilensky 1995; Smith 1995; Schatz 1995; Crum 1995] These are research projects to develop new technologies for digital libraries. Among the most important questions being addressed are billing, image handling, video indexing, and so on; a particularly critical one is the interworking of different digital libraries. Given the distribution of library resources around the United States, no one expects (or desires) that there would be only a single digital resource. This means that we need methods for finding either individual items or collections in different places, and assembling virtual collections that users can search or browse. Perhaps the University of Michigan project is most concentrated in this area, but all the projects are participating. Regular meetings among the digital library community (in fact too many meetings) are keeping them all in touch. See the map below for some of the projects.
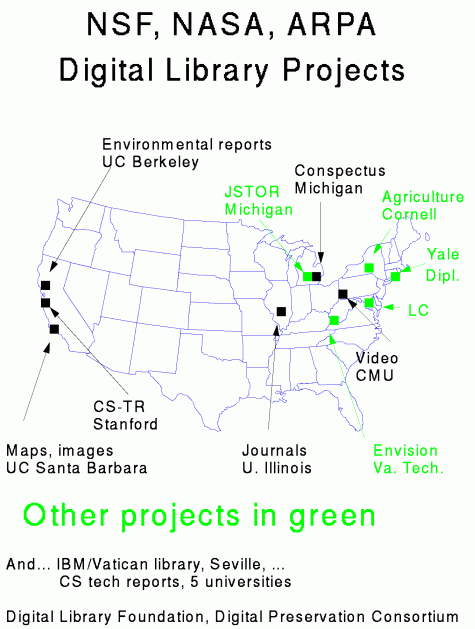
In addition to these scientifically-oriented projects, there are others working on a shorter time scale. Some scanning efforts originate from the commercial sector such as the Elsevier TULIP project (materials science journals) or Red Sage (biomedical journals, from AT&T and UCSF). Other projects originate from libraries. Cornell University, for example, is working on a major conversion of the basic agricultural literature of the 1850-1950 period, with the intent to distribute to many countries around the world. This project has two interesting sidelines: it is trying to track accurately the cost of clearing copyright on the 1920-1950 material, and it will produce preservation-quality microfilm as well as CD-ROMs to reassure the conservative. Harvard has done a very interesting project, converting approximately 80,000 Judaica posters to Photo CD form, and thus removing the need to handle a great many fragile items. This was an unusually economical project, costing $2 per picture (and converting 1000 images/day). The Mellon Foundation has funded the JSTOR project, which is scanning the complete run of ten major journals in economics and history. These journals occupy shelf space in many libraries, and JSTOR will see whether electronic surrogates can be effective in reducing space demands.
The number of imaging projects of this sort, of course, is now beyond any one person's ability to track. The Columbia Law Library has 250,000 pages of the FBI files on the Rosenberg atomic spy case. The U. S. Naval Research Laboratory has scanned 5,000,000 pages of 100,000 technical reports. GTE runs a system called Luminary which is storing 2 terabytes of engineering documentation. Yale wants to scan 10,000 books on diplomatic history, IBM wants to scan 70M pages from the Franklin D. Roosevelt library (plus a large fraction of the Vatican library incunabula). The most ambitious is that of the Library of Congress, which plans to put 5 million items relating to American history into machine-readable form [Becker 1995].
Many other projects are based on Ascii and deal with new material. There are many electronic journals now, one of the best known being Psycoloquy, edited by Steven Harnad. The high-energy physics community now depends on their preprint bulletin board, run by Paul Ginsparg at Los Alamos. Michael Hart runs Project Gutenberg, a volunteer effort in which people type in books (in the public domain) or donate material and it is added to their public files. A combination of MIT, CMU, Cornell, Berkeley, Stanford and USC is working on a major collection of computer science technical reports in machine-readable form (some scanned, some Ascii). Project Envision is working on machine-readable dissertations, operating out of Virginia Tech. OCLC is serving as the electronic printer for a few dozen electronic journals, working with publishers including AAAS and AIP.
There are four different projects I have heard about to get large quantities of monograph tables of contents. CMU is typing them in, as I believe is Blackwell's, the Library of Congress (Sarah Thomas) is getting some of them by electronic transfer from the publishers, and a group in Bavaria led by the Technical University of Munich (Rudolf Bayer) has a project named OMNIS/Myriad which is doing scanning and OCR. Each of these projects is aiming at better searching of monographs, which traditionally are not abstracted and thus are harder to search than journal articles.
Finally, in terms of quantity all of these projects are overwhelmed by the Web and Mosaic. There are over 4 million Mosaic pages tracked by Lycos at the moment \- CMU guesses there might be a total of 12 million. Unfortunately, by traditional library standards much of this is very low quality, very ephermeral, and hard to find. We have, to some extent, reverted to a world in which people write letters to their friends and point them to other information resources. We do not have digital libraries as much as we have digital graffiti in the ether. There are numerous projects providing retrieval for this material (such as Lycos and InfoSeek), plus a few providing organization (Yahoo and OCLC). Right now, however, there is no one taking responsibility for selecting pages that should be preserved and keeping them (among other things this violates the copyright law). We need some kind of library/archive solution to the problem of rapidly disappearing Web resources.
Information, everyone believes, is critical to the economic future.

In practical terms, it is likely that provision of current material will move back towards the publishers. It is in this way that the real savings in information handling can be realized; the question is in fact whether the publishers too will be bypassed, as the authors self-publish on the Net or through some new venture. Just as universities find their professors preferring to think of themselves as members of an `invisible college' rather than as members of the real one at which they teach, they may find that their staff, as readers, prefers to read directly from the sources, rather than through the library.
Traditionally, libraries operated as a way of sharing books. In the new electronic world, publishers can have sufficient control of who reads what that they need not allow sharing if they do not wish to. It may be economically sensible for them to provide sharing \- discounts for bulk purchases are not uncommon in many industries \- but there is no need for libraries to arrange this sharing. We can expect publishers to attempt to manage the use of new books within universities themselves, since in the electronic world there may not be any difference between the accessibility of a file ``delivered to the library'' and a file ``delivered to a desk'' \- both will just be an electronic file one can view. The difficulty is that neither the publisher nor the library can afford to imagine that university purchase funds will replace all book purchases by individual faculty. Thus, the first use of electronic pricing is going to be for the very expensive scientific journals where there are no individual subscriptions anyway.
Pricing of books is likely to be very unstable for a while in the electronic world. Economists have a habit of saying ``price equals incremental cost,'' a maxim that made some sense in 18th century tin mines when incremental cost was higher than average cost. However in the information industries, incremental cost is much lower than average cost, and in the online information business, incremental cost is very close to zero. As a result it is not possible to come up with stable prices in a traditional economic model, and we can expect price wars and attempts to limit usage in strange ways [Lesk 1992]. Airlines, regrettably, are probably a good model for what will happen: very complex prices, attempts to minimize transfers and sharing, and attempts, probably fruitless, to persuade libraries and universities to limit the range of suppliers from whom they buy materials. One step publishers are likely to take is to time-limit all subscriptions at first, which will give them an opportunity to correct pricing decisions that turn out to be wrong.
Libraries will not be enthusiastic about time-limited usage, however. They are accustomed to purchasing material and expecting to have it forever. Although a library may drop a subscription to a journal, it does not then remove the back issues from the shelves. In the new world, it is likely that the 1995 payment to a publisher will buy access to the whole file of a journal for users reading it during 1995, rather than adding the 1995 issues to a previously bought backfile. Although this will upset librarians, it might be an improvement for the readers. If everything were priced separately, would users prefer access to back issues, or to a larger variety of current journals? One suspects the current publications are more valuable.
However, what happens when the back issues are worth so little that it no longer pays the publisher to keep them online and accessible? Who will take over? Today, libraries and archives serve the function of preserving old material. Tomorrow, they expect to do the same. The problem is not that publishers will be unwilling to transfer the rights to worthless material to libraries; one suspects they will be even eager to do so. The problem is that if all new material is being provided by another mechanism, and the libraries are restricted to material that really isn't wanted very much, who is going to fund the libraries? It is hard enough to get budget resources for libraries when they are the only practical way on campus to get many current journals. It is going to be really hard when the only books and journals the readers are getting from the library are old and rarely used. 6. Copyright.
It is not possible to write about digital libraries without getting involved in arguments about the copyright law. In the United States, material goes out of copyright after 75 years. Although the law relating to books published more than about 40 years ago is confusing, no book printed after 1920 can be assumed to be public domain. It is not easy to find out who owns the copyright for many items, and it may be both time-consuming and expensive to obtain the right to scan items or otherwise duplicate them. Although US law gives libraries special rights to copy material for reasons of preservation, this only applies to analog copies, not digital copies.
In the digital domain, there has even been a proposal to abolish the ``fair use'' concept, under which some small degree of copying was deemed legal. The wording of the proposed rule is so strict that it is not even clear that ordinary transmission of electronic mail messages doesn't infringe it (since the message is stored and retransmitted from several sites along the path). It would be desirable if the copyright law permitted libraries to make copies of out-of-print materials, or provided some straightforward mechanism for buying the rights to such materials; but this seems unlikely. Much of the political pressure in the United States is aimed at expanding copyright (a 20-year extension of the basic period is now under consideration in Congress).
The practical effect of the copyright problems is likely to be threefold. One is that the publishers, who own the copyrights for most of the valuable material, will have an easier time than the other participants in this business who have to negotiate rights. The second is that the imagined open world of self-publishing is likely to be less successful than its proponents think, because of the difficulty of dealing with all the different individual authors if one is trying to make compilations or abstracts or whatever. Negotiating with the commercial publishers is a fairly rational process and it is possible to clear the rights to many articles or books at once in a single deal. Negotiating with a large number of individual professors is likely to be hopeless. The third outcome, unfortunately, may be that countries who take a more lax view of copyright enforcement may gain some temporary advantages in developing information systems. We have always had book pirates (Ireland once upon a time, the United States in the 19th century, and at one point the Soviet Union). The Internet is likely to make state-tolerated piracy a much more serious problem.
Downstream piracy by individuals is the major problem limiting the willingness of publishers to enter the online publishing business. Too many talks about the `nationwide file system' and too much memory of the software games industry being destroyed in the 1970s has lead to much research on how to stop illegal copies, but not enough progress. It is hard to see how individuals can be stopped from taking screen dumps. This will not steal things rapidly enough to be a threat, however. More serious is the sale of software that will be devoted to stealing things and the United States has proposed to outlaw such programs.
Perhaps the most important issue facing us in designing the rules under which digital libraries should operate is the issue of diversity. Will we expect that the new world will have fewer publications or more publications? The economics are unclear. On the one hand, incremental cost for electronic distribution is so low that a natural monopoly might develop, in which the first book on a subject might be sold at a price which prevented anyone else from trying to compete. On the other hand, the cost of producing a simple Ascii-only book seems to be very low also, so that the cost of entry seems low and many authors and publishers should appear. However, the apparent low cost of entry is somewhat deceptive. The cost of producing high-quality multimedia right now is very large (partly because buying the rights to photographs is so expensive that one winds up paying to take new photographs). This pushes towards a natural monopoly, at least for the glitzy material.

Software production seems to be the best model. There is a huge quantity of ``shareware'' out there, of doubtful quality; but it is not easy for a new entrant in the database or spreadsheet business to compete with companies like Microsoft, IBM, or Oracle. The same could easily happen in information provision, as it to some extent already is happening with books: easy availability of a few best-sellers, difficulty in obtaining anything else. In fact, on the high-energy physics preprint board there is already a phenomenon in which the lack of refereeing means that people only read papers written by famous authors, making it harder than in traditional journals for a new researcher to break into the field.
The question is whether lack of diversity is good or bad. Nobody thinks that having ten different people key in the same railway timetable would be a valuable use of time, and the ability of computers to let us easily share one copy would clearly be good. Many other kinds of mechanical reproduction clearly save effort. But many of us in the United States have doubts about seeing every student learn history from the same textbook or multimedia/video program. As should be clear from the discussion of projects, the United States has a wide diversity of library projects and is not likely to support any kind of central archive of digital library material or central control of what is available. We would like continue a tradition in which many different opinions are easily published and distributed. The problem is to do so in a way that does not just leave people drowning in junk \- it would be possible to take every speech at Hyde Park Corner and put it on the Internet, but I doubt it would be found valuable.
There are things we can do to manipulate the system. There is a technological conflict right now between communications systems that are symmetric (e.g. the Internet) and those that are asymmetric (e.g. direct broadcast satellite). Obviously the symmetric systems encourage publication, and could be encouraged. But merely making it possible to distribute lots of stuff is not enough. There is plenty of junk on the Internet right now. We need to find ways in which good material can be encouraged even if it is not mass market, but we can not afford to encourage every source of bits without limit.
And this brings us back to libraries. Earlier I noted that libraries were rewarded mostly for buying things, not for how they delivered them to users. In the future this has to reverse. Libraries are probably not going to be the agents of information delivery, but they still need to be the agents of information selection. If we wish to have many items published and available without drowning, we need collection management, reviewing, recommending, and other methods of sorting out what information people would want to read. This is a traditional job for libraries, and we need to make a transition, so that libraries are rewarded for this job, and so that readers are aware that libraries are the solution to the problem of too much junk. From the vast quantities of stuff that are out there, libraries have to select what a university wants to have around, learn to direct people to what they need, and keep track of what else is there. If we think of information in the future as an ocean, it will no longer be the job of libraries to provide the water; but it will be their job to provide the boats.
[Becker 1995]. Herbert Becker, "Library of Congress Digital Library Effort," Comm. ACM 38 (4), pp. 66 (1995).
[Berners-Lee 1992]. T. Berners-Lee, R. Caillau, J. Groff, and B. Pollerman; "World-Wide Web: the Information Universe," Electronic Networking: Research, Applications, Policy, 1, (2), pp. 52-58 (1992).
[Bush 1945]. Vannevar Bush, "As We May Think," Atlantic Monthly 176 pp. 101-108 (July 1945).
[Christel 1995]. M. Christel, T. Kanade, M. Mauldin, R. Reddy, M. Sirbu, S. Stevens, and H. Wactlar; "Informedia Digital Video Library," Comm. ACM 38, (4) pp. 57-58 (1995).
[Crum 1995]. Laurie Crum, "University of Michigan Digital Library Project," Comm. ACM 38 (4), pp. 63-64, (1995).
[Cummings 1992]. Anthony M. Cummings, University Libraries & Scholarly Communication: Study Prepared for the Andrew W. Mellon Foundation, Association of Research Libraries, Washington, DC (Dec. 1992).
[Egan 1991]. D. E. Egan, M. E. Lesk, R. D. Ketchum, C. C. Lochbaum, J. R. Remde, M. Littman, and T. K. Landauer; "Hypertext for the Electronic Library? CORE sample results," Proc. Hypertext '91 299-312, San Antonio, Texas (15-18 Dec. 1991).
[Garcia-Molina 1995]. Stanford Digital Library Group (Hector Garcia-Molina et al.), "The Stanford Digital Library Project," Comm. ACM 38, (4) pp. 59-60 (1995).
Kenney, Anne and Lynne Personius; Joint Study in Digital Preservation, Commission on Preservation and Access, 47pp. (Sept. 1992), ISBN 1-887334-17-3.
[Lesk 1992]. Michael Lesk, "Pricing electronic information," Serials Review, 18, (1-2), pp. 38-40 (Spring-Summer 1992).
[Lesk 1994a]. M. Lesk, "Experiments on Access to Digital Libraries: How can Images and Text be Used Together?" Proc. 20th VLDB Conference, pp. 655-667, Santiago, Chile (September, 1994).
[Lesk 1994b]. Michael E. Lesk, "Electronic Chemical Journals," Analytical Chemistry, 66 (14), pp. 747A-755A (July 15, 1994).
[Odlyzko 1994]. Andrew Odlyzko, "Tragic Loss or Good Riddance: The impending demise of traditional scholarly journals," Notes of the AMS, (1994).
[Schatz 1995]. Bruce Schatz, "Building the Interspace: The Illinois Digital Library Project," Comm. ACM 38 (4) pp. 62-63 (1995).
[Smith 1995]. Terence Smith and James Frew; "Alexandria Digital Library Project," Comm. ACM 38 (4), pp. 61-62 (1995).
[Wilensky 1995]. R. Wilensky, "UC Berkeley's Digital Library Project," Comm. ACM 38 (4) pp. 60 (1995).