Will libraries be marginalized in the future world of information handling? The costs of the current system of scholarly publishing are going out of sight, the financial support for libraries is deteriorating, and much of what we need to know is on the Web instead of in books. The "killer ap" for the NII has turned out to be browsing multimedia information; it appears to be displacing CD-ROM games as nerd recreation.
If old books are scanned, new books are unaffordable, and students get their information from terminals, what should libraries do? Libraries need to cooperate and convert, retaining their roles as guidance and training while substituting access for collecting. Computer prices are declining so rapidly that this will even be economical, as scanning becomes cheaper than building shelf space. However, the competition for access to the student desktop is going to be severe; libraries have to act, and to use their skills at organization and selection to become the university's agent for buying information.
Looking at the number of books bought by American research libraries compared with the number of books published in the United States, libraries are about back to where they were in the 1920s. [Cummings 1992]. The amount of information continues to increase. Odlyzko [Odlyzko 1995]. estimates that the number of mathematics papers published each year doubles each decade, growing from 840 papers/year in 1870 to 50,000 per year today. The journals in which these papers publish grow ever more expensive as well as ever more voluminous. Even the abstract journals that began around the beginning of the century as a solution to the information glut of that time are now being priced out of reach. In the 1950s, for example, individual chemists could afford to buy Chemical Abstracts and could actually read the parts of it they cared about. Today CA costs $17,400 per year, and no individual could either afford it, have the time to read it, or have the shelf space (or, for that matter, the office floor loading capacity) to keep it.
The costs of passing the information from authors to readers have become intolerable. The Harvard University libraries subscribe to 96,000 serials. Harvard has about 2,000 faculty members. Does anyone really believe that even the average Harvard faculty member can keep up with 50 journals? The publication cost of the average mathematics paper is about $4,000. American mathematics research organizations (universities and corporations) spend as much buying journals as NSF spends funding math research. Odlyzko estimates that the cost per reading of a mathematics research article is over $200 (given that the typical article is read 20 times or less). Would any mathematician actually pay $200 to read a paper, if they had the choice? At what point, given the squeeze on faculty positions, will a mathematics department realize that they could trade their library holdings for another member of their department, and decide it would be a good deal?
Steve Harnad has written eloquently about this problem. [Okerson 1994]. Scholarly publishing is not reader-driven; it is author-driven, with those desperate for tenure dividing their research into ever smaller units and putting it in more and more journals. Publishers have discovered that libraries will pay amazing prices for journals, since each particular journal is available from only one source. The few fraudulent faculty who have obtained tenure by copying articles from one obscure journal to another are matched by publication strategies such as the artificially scarce (and fake) pamphlets exposed by Carter and Pollard.
The system is breaking down everywhere. I attended a meeting in 1993 in London at which Sir Peter Swinnerton-Dyer, speaking for the university funding organization, eloquently pleaded with publishers, saying that they could either work with the university libraries to build a system that was cheaper and better or the universities would be forced to do something that was cheaper and worse. Even major research libraries have had to drastically cut their purchases, move books to outhouse stores, and otherwise accomodate the financial constraints that affect universities. Some, such as the United Engineering Library, have had to close down.
California, as they say, always gets there first. The state now spends more money on its prisons than its universities. And from 1977 to 1993, it cut the number of hours California public libraries were open (per resident) by more than half. And rumors suggest that some California campuses are suggesting doing without a physical library (as has also been suggested by De Montfort University for its Milton Keynes campus) and that other smaller campuses in the state system might outsource their library to the UC libraries.
California, of course, is also the site of Silicon Valley. For twenty years, we have seen electronic information starting to replace paper. In 1969 the Library of Congress started to distribute catalog records in machine readable form, and during the 1980s many libraries adopted online catalogs as a replacement for the traditional cards. The 1970s also saw the general use of online abstract journals. Although I could not afford to buy Chemical Abstracts on paper, I have better access to it today through online services than I would have if it were in the local library.
I routinely ask audiences at talks whether the last thing they looked up was on a screen or on paper; in the US the usual academic audience has been saying 75% on screens. Some scientific areas are dominated by online information; the Web, for example, is the best place to get descriptions of the latest computer products. Other areas which rely on computerized information include high-energy physics, which depends on the preprint bulletin board run by Paul Ginsparg at Los Alamos, and biotechnology, where protein and DNA structure are passed online, not through paper publications. The importance of the physics preprint system was proven a few years ago when the organizer proposed to shut it down for lack of time to do the administrative tasks; the outcry around the world was such that his laboratory assigned him a clerical assistant to keep the system running. [Taubes 1993].
The most recent explosion in online information is of course the World Wide Web. [Berners-Lee 1992]. Everyone from bagel shops to law firms now has a home page. Web page construction is an instant industry, and numerous commercial plans for competitive services have been abandoned as everyone seeks to join the Web. The Alta Vista search engine is now finding (April 1996) 170 gigabytes of HTML on the Web; this is the equivalent of the equivalent of perhaps 200,000 books, and the Web is doubling in size every five months. Self-publishing on the Web is growing rapidly, as more and more people put their latest papers online. I have even started recovering some of my own older papers and adding them to my web site.
Despite the size of the Web, it is still smaller than some of the large commercial online services. Mead Data Central has about 2.4 Terabytes online (the equivalent of a library of over a million books). Information retrieval is one of the United States' most successful industries, in fact. The total business in online information services is about $15B at the moment, comparable to all of book publishing. The rate of subscriber growth is 25% generally and 44% among consumers rather than businesses. 30% of the sales go overseas. [Hillstrom 1994]. In 1989 Dialog was sold for $353M, while in 1994 Mead Data Central (about double the size) went for $1.5B. US exports are eight times our imports, as shown in the table below.
| US Trade Balance in Information Services | ||
|---|---|---|
| 1994 | Exports | Imports |
| Whole world | $3.2B | $.4B |
| EU | 1.3B | .3B |
| Japan | .4B | .01B |
Although the Web may still be catching up to the previous online services, it is catching up very fast. The packets on the Web are now the largest source of traffic on the Internet, and everyone recognizes that the Internet is in fact the NII (National Information Infrastructure), forgetting discussions of a few years ago about whether some kind of new structure would replace the Internet. About two years ago the Internet had about 1/1000 the traffic (in bytes) of the voice telephone network; doubling every year, this means the Net will catch up early in the next century. In terms of switching capacity it may be ahead right now (remember that the Internet switches every packet, averaging perhaps 50 bytes, while a voice phone call is switched only once, which for a 3-minute call at 56 Kb/s means that 1.5MB are sent per switching operation.
The Web is clearly the "killer ap" for the NII. A few years ago, people speculated about what the driving force would be to cause the NII to come into being. Many thought home video would be the answer; others considered games or banking transactions. Despite many attempts at video-on-demand experiments, email, chat and Web browsing are clearly more successful (and more affordable economically). The number of people able to connect to the Web is estimated from 10 million to 50 million, depending on who is counting and why. American On Line (AOL) even talks about its "rating": it had, one week in December, about 2/3 as many households online as were watching CNN. In late 1995 CD-ROM sales abruptly slowed, and the most obvious explanation is that the CD-ROM fanatics had switched to web surfing. Netscape gets 45 million hits a day; Alta Vista is doing 3 to 4 million searches a day.
The Web is rapidly becoming commercial, as well. About $350M worth of products (mostly airline tickets) were sold on the Web in 1995, and some $70M of advertising will be bought this year (although 4th quarter 1995 was only $12M; growth is slowing down). At the turn of the century, Web advertising is expected to reach $2B. These estimates are from Forrester Research studies. Web page owners are able to charge advertisers some 3 to 5 cents per exposure, a price in excess of that charged by network television or national magazines. [Hillstrom ]. Remember that Web ads are more easily targeted and the Web population is quite wealthy (computers are expensive enough that the average internet user is in a household with a yearly income of $62,000). Every large communications company is talking about its "Internet strategy" and surely no one is unaware of the stock market flotation of Netscape, in which a company with no history of profit has been valued at up to 6 billion dollars. The Yahoo IPO was also oversubscribed and its stock price doubled the first day.
Related industries are also successful. For years text
retrieval was an academic specialty, with relatively
little commercial impact. Now, as innumerable internal
and external systems attempt to provide access to the
many documents prepared in machine-readable form, text
retrieval is booming, and even the academic research
algorithms are being used as boasts to advertise particular
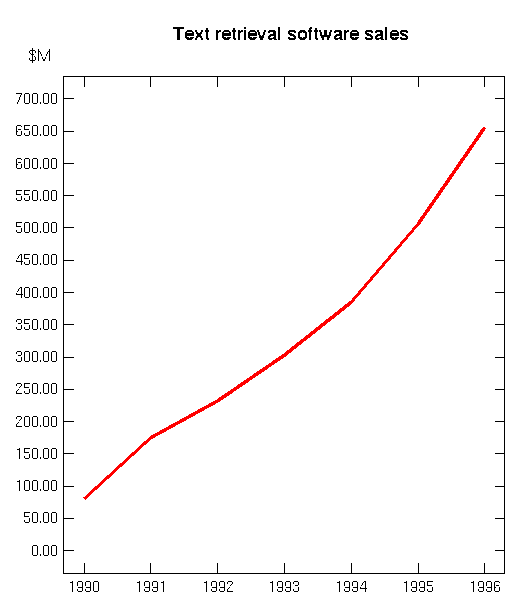
search systems. Figure 1 shows the
growth in sales of text retrieval software. And books about
the Internet now take more shelf space than cat cartoon books.
What does this mean for libraries? If the Web becomes commercial, do libraries have a role in digital information? If libraries do not have a role in digital information, then what will happen to them in the future? Perhaps students and scholars will get their information directly from publishers, bypassing libraries. If this happens, libraries might find themselves in a backwater, having perhaps the status and public visibility that archives or herbaria have today.
Fortunately, libraries are major participants in the US digital information projects sponsored by NSF, ARPA and NASA. In these projects, libraries are helping develop technology to organize and deliver current information from traditional publishers, television stations, and other sources. The proliferation of Web material has meant increased interest in some traditional skills of librarians: deciding what to keep and how to organize it. There is much for libraries to contribute in this area; the average URL, for example, has a life of 44 days, so that the Web is perhaps more like a newsstand than a library.
As examples, the University of Michigan Conspectus effort is showing how disparate collections can be combined to show the user a single access point to different electronic resources. The University of California Berkeley "finding aids" project helps organize electronic versions of traditional comment and directory items, while their "multivalent document" research shows how to relate different formats of the same or similar information. And the UCSB Alexandria project unifies different kinds of geospatial imagery (maps, aerial photographs, and the like).
However, much of the electronic effort is coming from publishers. Newspapers such as the New York Times, The Times (London), and the Telegraph are available online. UMI sells a wide variety of journals on CD-ROM, including all the IEEE journals as examples. Elsevier is prepared to provide a great many of their journals in electronic format, and many pharmaceutical company libraries are preferring to get only electronic format for some of their journals. Many of the CD-ROM systems are intended for libraries and are priced accordingly.
However, a number of alternative pricing models exist. Some CD-ROMs are sold outright at prices users can afford, even if the traditional book was too bulky for most consumers to buy; an example is the Oxford English Dictionary. Such companies as Open Market Systems support pricing by the item, and sell individual articles for a few dollars (eg for Lexis/Nexis or Time-Warner). A new company called the Electric Library sells a variety of online publications (aimed at high school students) for a flat $10/month. And of course the Dialog or BRS pricing models of so much per minute are still being used.
Many publishers are also eyeing the textbook market as an obvious place to use electronic distribution. Textbooks are profitable today (unlike many scholarly monographs), and part of the competition is the second-hand book market. In traditional paper publication, it is not practical to issue new editions of books more than about every three years. In electronic form, merely changing the exercises in the books every six months would be easy and would severely impact the used book market. Also, tailoring material for individual professors' needs would be relatively easy, as well as allowing the individual teacher to add annotations for his or her class only. Ownership of individual computers is very high among students and many universities have wired data connections into each dormitory room. Thus, online textbooks look very attractive to publishers, and are only being delayed by lack of anti-piracy technology.
Library economics make them vulnerable to suggestions of bypass.
Figure 2 shows the typical allocation of university, library and
trade publisher budgets. Since the typical US library spends perhaps
one-third of its budget on acquisitions, a suggestion that students could
buy information directly holds great attraction for university bean counters.
It would be even more economical to dispense with the faculty, but that
is not yet a practical discussion.

Unfortunately for librarians, much of the publisher-driven projects do involve direct information sales to end users. There is a perceived competition for control of information delivery to students; I have heard organizations ranging from publishers to wholesalers, booksellers, university computer centers, university telecommunications operators, and online service providers suggesting that they should lay claim to this area. If information goes directly to students from the publishers, what is the role of the library? If the textbook and current reference material, the material in greatest demand today, moves to the students without going through the library, how much will the patronage of the library decline?
Libraries are also doing a great deal of work in retrospective
conversion. We are about to see a transition in which libraries
realize that it is cheaper to scan books and store them electronically
than it is to build on-campus shelves to store them. The CLASS
project at Cornell produced estimates of $30 to $40 per book for
scanning costs,
[Kenney 1992].
a price which is likely to go down as technology
improves. Building library stacks, by comparison, was recently $20/book
at Cornell (Olin library extension) and $30/book at Berkeley. Now
these prices are relatively high due to underground construction,
and in the case of Berkeley resistance to a force-8 earthquake.
But the typical US university has no convenient space left on central
campus, and is facing high construction costs to build any kind of
book stack.
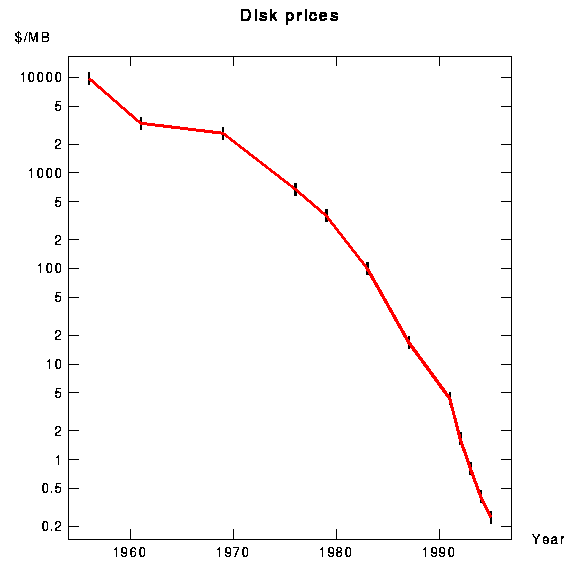
And while computer prices keep coming down, with small scanners at $300
and fast ones at $5000, construction costs are increasing. Even at
campuses with cheaper land, there is no hope of keeping up with the
decline in disk prices shown in Figure 3.
An alternative to an on-campus building, with expensive architecture and construction, is off-campus storage in a cheap building followed by retrieval-on-demand. This model is that followed by Harvard with its Depository, built on less expensive land for $2/book. However, each retrieval costs perhaps $3/book. The cost of book storage in this building plus retrieval must be compared with the cost of electronic storage plus amortized refreshing and maintenance. Of course the librarian must also judge the relative importance of the instant retrieval offered by computer screens and the physical appearance of the conventional book. Even if the instantaneous availability of the digital material is ignored as an advance, economics are driving libraries towards the digital model, since again computer prices are going down while the costs of driving vans from building to building are going up. Donald Waters has computed the expected costs of both models, and his results are shown in the next table. [Garrett 1995].
| Cost of off-campus library vs. digital storage (from Don Waters) | ||||
|---|---|---|---|---|
| Year 1 | Year 4 | Year 7 | Year 10 | Depository Library |
| Depository Storage Costs Per Volume | $0.24 | $0.27 | $0.30 | $0.34 |
| Depository Access Costs Per Volume Used | $3.97 | $4.46 | $5.02 | $5.64 | Digital Archive |
| Digital Storage Costs Per Volume | $2.77 | $1.83 | $1.21 | $0.80 |
| Digital Access Costs | $6.65 | $4.76 | $3.51 | $2.70 |
The JSTOR project is a well known attempt to implement this strategy, supported by the Andrew W. Mellon foundation. [Bowen 1995]. JSTOR has scanned ten journals in economics and history back to their first issue. The journals were selected because they are widely held in American libraries. Both page images and cleaned-up text are to be available. The intent of JSTOR is to see if libraries can in fact relieve shelf space crowding by substituting use of the electronic images for the paper.
Given this economics it is already true that if a group of libraries, even three or four, were all planning to build new storage or on-campus buildings; and if they could identify a large number of pre-1920 books that they all held, their universities would save money by scanning instead of building. Of course, in many universities the cost of space is not monetized, and there would be no way to trade the cost of the building for the computer equipment needed in place of it. Some of this is merely a gap in university accounting; some is a legitimate fear that it is much easier to get rich alumni (or state legislators) to provide money for buildings than for equipment of low public visibility.
The previous paragraph also suggests that the different libraries would coordinate their strategies. Although libraries have a good record of cooperation on subjects like inter-library loan, joint microfilming, and collective cataloging, cooperation among different universities is rarely easy. This raises another possibility: instead of such a project being done jointly, it will be done by one library, which then deliberately sells access to the result to other universities at the administrative level, possibly over the objections of the receiving librarians.
This would continue a trend we are seeing towards remote education in universities. University administrators see providing long distance services to students as a solution to the increasing costs of education. The University of Kansas teaches library students in Oregon. MIT has business school students in Hong Kong. Why should university administrators not think that the same idea would apply to libraries?
The discussion of scanning above mentioned "pre-1920" books. This is, in the USA, the magic threshold for books that are out of copyright. Unfortunately, any discussion of digital libraries must involve some consideration of copyright law. Cornell is testing the practicality of scanning books published after 1920, measuring the work involved in obtaining permission. Until now, all we have had is horror stories. IBM prepared a CD-ROM for the 500th anniversary of the voyage of Christopher Columbus; it is said that they spent $1M on clearing rights, of which only $10K went to rights holders. I assigned a class of students the task of writing a publisher asking for permission to digitize something and offering to pay. Of 18 different publishers, only six answered the letter at all (after two months); only two actually quoted a price.
Things are getting steadily worse, in fact. The US has repealed its requirement for copyrighted works to contain a notice with the name of the copyright holder; and there are no incentives to encourage registration with the Copyright Office. The term of copyright will change (in the next century) from the easily computed 75 years from date of publication to life of author plus 50 years, requiring some research perhaps even to find the author's name. A proposed revision to the copyright law will extend the term by 20 years, and make unambiguously clear that digital transmission or display of a document is a copy, so that no kind of digitization or viewing will escape the need for permission and license. On the other hand, the publishers wish to have digital transmission carefully distinguished from publication, no matter how many copies are sent out, so that they do not incur the obligation to deposit the work with the Library of Congress.
The proposal for revision of the law now being considered has only one advantage for libraries. There is a special exemption in the law which permits libraries to make copies of deteriorating works for purposes of preservation, but today this copy must be an analog copy, not a digital one. The so-called White Paper on copyright law revision will permit libraries to use digital technology for preservation. With luck, the US Congress will not discover the Australian rule that if a work is duplication for purposes of preservation the original must be destroyed, and decide to enact it.
Unfortunately the new law revision also contains a variety of restrictions, the most important one probably being the complete removal of "fair use" on digital works. No quoting, browsing, or even displaying of a digital work is permitted without the copyright holder's permission. If this philosophy continues, libraries in the digital world will function only as the agents of publishers. They will not be able to set their own policies for access to work and whether or not to charge for services; these may be imposed by the license agreements that will come along with works in the digital world. [Samuelson Spring 95].
In the context of "self-publishing" this may get even worse. Even if one considers the major publishers to be unreasonable in their demands for permissions and royalties, at least there are only a few of them and they are only accused of being greedy, not irrational. If every single copyright were to remain with the individual author, the amount of negotiation to produce any kind of compilation or comparison will become enormous and it is not clear that even lots of money will persuade some people to relax control over their work.
The publishers do have serious problems. In the early 1980s there was a thriving business in selling computer games for the first PC machines, and it was destroyed by people illegally copying the game programs. Software piracy is rampant today, with some countries (e.g. Thailand or Poland) containing almost no legal software, with virtually all of their software in the form of pirate copies. Even in more responsible markets the situation is very serious. The Software Publishers Association estimates their loss to piracy at $3B per year in Japan and $1B per year in Germany. The most intractable problem is the downstream problem; suppose someone has bought a legal copy, how can they be kept from passing it on to someone else?
Nevertheless, in the future we are unlikely to be able to do things that we do routinely today. For example, under the right of first sale, a purchaser of a book can read it and then pass it on to someone else. In an electronic world, it is going to be hard to see how to retain this rule, since almost certainly the "passing on" will involve electronic mail or some other transmission that will be called copying. Out of print books may become entirely 'unavailable' since libraries may not own copies, but only rights to access works on a publisher database; should the publisher go bankrupt or just decide that the market for this particular work does not justify keeping it in existence, it will be gone.
The scenarios outlined above are fairly depressing for a librarian. Collections will divide into three categories. Works published before 1920 will have been scanned and stored at some few large repositories, with smaller libraries being bypassed by users connecting directly to these services. Current and recent material will be on license from publishers, with no actual copies at the library, and no control of the policy of accessing these works. Only a strange pile of 1920-1990 books, sort of the Sargasso Sea of publishing, will be remain in the stacks, only available at the library. Everything else will have been pushed off to electronic form, leaving enormous gaps in the collections. The remaining books, not being searchable, will be viewed by students as so hard to use that few will come to read them.
The students and scholars will have their problems, too. Yes, they will be able to get everything except the copyright doldrums from their desktop, but they may not like the charges imposed and are not likely to have much bargaining power to do anything about it. The frustration of not being able to reaccess something for free nor to download it legally is not likely to be alleviated by the thought that they can copy it out with pen and ink.
We all also worry about the student of the future, staying perpetually in a dorm room in front of a workstation; will these students develop any social skills? I was once told at Columbia that this fear was exaggerated; in the days of card catalogs nearly all users were alone, while at the OPAC terminals one frequently saw two or three students in a group, with one explaining to the others how to do something. The idea that we improve student socialization by providing bad human interfaces may be a temporary solution, but it is unlikely to last.
What should libraries do to avoid this pessimistic future? They must
Fortunately, libraries have a good history of doing these things; what they do not have is high visibility for their value. Libraries have long cooperated on interlibrary loan and microfilming, for example. The same attitude can be applied to electronic resources, in which we have libraries sharing rather competing for the right (or the funding) to scan particular items. We could move from shared cataloging to shared conversion, storage and access across the country. Libraries could also cooperate with the faculty at their universities to provide alternative electronic journals, with rapid publication, on-demand printing, and some degree of permanence and credit.
Similarly, libraries should cooperate on electronic acquisitions. The United Kingdom Office of Library Networking (UKOLN) has been negotiating UK-wide academic site licenses for electronic information. The combined bargaining power of all higher education libraries has permitted better standardization and negotiation than any library could obtain separately. US libraries should work together and with their universities, as suggested by Brian Hawkins and others, [Hawkins 1994]. to gain a place as the deliverers of information to the campus. They should also work together to establish standards and software packages suitable for academic use. Just as universities such as the University of California pioneered online catalogs, universities and their libraries should continue the implementation of primary journal access software (as is happening at places like Michigan and Illinois) to see that academic principles are carried through in new systems of information delivery.
Finally, libraries must emphasize their role in training. University faculty tell students what the faculty think they should know. Libraries tell the students what the students what to know. Today libraries are rated too much by how many books they have, rather than by how many users they have and how much help they give them. As the number of books in the stacks becomes less important, the amount of help offered will become more important. Libraries must count and emphasize the value of these services. On the ocean of information that will float around the NII in the future, the responsibility of libraries will be to provide the sextants, not the water.
[Berners-Lee 1992]. T. Berners-Lee, R. Caillau, J. Groff, and B. Pollerman; "World-Wide Web: the Information Universe," Electronic Networking: Research, Applications, Policy 1 (2) pp. 52-58 (1992).
[Bowen 1995]. W. G. Bowen JSTOR and the Economics of Scholarly Communication Council on Library Resources (September 18, 1995). Web: http://www-clr.stanford.edu/clr/econ/jstor.html.
[Cummings 1992]. Anthony M. Cummings University Libraries & Scholarly Communication: Study Prepared for the Andrew W. Mellon Foundation Association of Research Libraries (Dec. 1992).
[Garrett 1995]. John Garrett, and Don Waters Preserving Digital Information Research Libraries Group and Commission on Preservation and Access (1995). Web: http://www-rlg.stanford.edu/ArchTF.
[Hawkins 1994]. Brian L. Hawkins; "Planning for the National Electronic Library," EDUCOM Review 29 (3) pp. 19-29 (May-June 1994).
[Hillstrom 1994]. Kevin Hillstrom The Encyclopedia of American Industries, vol 2 Gale Research (1994).
[Hillstrom]. Prospectus for Yahoo initial public offering On the web at http://ipo.yahoo.com.
[Kenney 1992]. A. Kenney, and L. Personius Joint Study in Digital Preservation Commission on Preservation and Access (1992). ISBN 1-887334-17-3.
[Odlyzko 1995]. Andrew Odlyzko; "Tragic Loss or Good Riddance: The impending demise of traditional scholarly journals," International Journal of Human-Computer Studies 42 (1) pp. 71-122 (1995).
[Okerson 1994]. Ann Okerson, and James O'Donnell Scholarly Journals at the Crossroads: A Subversive Proposal for Electronic Publishing Association of Research Libraries (1994).
[Samuelson Spring 95]. Pamela Samuelson; "Copyright's fair use doctrine and digital data," Publishing Research Quarterly 11 (1) pp. 27-39 (Spring 95).
[Taubes 1993]. G. Taubes; "E-mail withdrawal prompts spasm," Science 262 (5131) pp. 173-174 (Oct. 8, 1993).