
 Note that the Pixlook interface is basically pretty routine:
the displays will normally look just like the printed pages.
Note that the Pixlook interface is basically pretty routine:
the displays will normally look just like the printed pages.
In the CORE project (Chemistry On-line Retrieval Experiment), Cornell University is experimenting along with Bellcore, the American Chemical Society, Chemical Abstracts Service, OCLC, and University College London with the provision of primary journal material in electronic form [Lesk 1991]. In the course of this project we have been accumulating and displaying to chemists the contents of the American Chemical Society primary journals, a group of twenty of the most important journals for chemical researchers. The material is available both as typesetting tapes, and thus in Ascii, and also as scanned page images. Thus, we have the opportunity to compare the relative advantages of both image and text display for chemical material.
In past experiments, it has been surprisingly common for hypertext systems to be no more effective than paper when measured in actual experiments. Such results can be found in [Gordon 1988], [McKnight 1989], [Marchionini 1988], and [Kaindl 1992].
The goal of the data preparation stage of the project is to arrive at two different computer representations of each article. One is the scanned images of each page of the article; the other is the combination of the marked-up Ascii text of the article and its tables, with bitmap images of the equations, figures, and other graphics.
The bitmap images of each page of the article are obtained by scanning at 300 dpi either the printed pages (for the articles published in 1991 or later), or the microfilm of the back issues (roughly 1980-1990). The scanning of the paper is done at Bellcore on an Improvision sheetfed scanner connected to a Sun-3 at about 20 pages per minute; the scanning of the microfilm is done either at Bellcore on a Mekel microfilm digitizer, at about 30 pages per minute, or by one of two outside contractors (STS Information Systems or Zuma Imaging). The microfilm is 16mm blipped cartridges (both vendors have commented on the high quality of the film).
The Ascii text is more complex to obtain. Typesetting tapes in a proprietary format are received from ACS and CAS, containing respectively the data used to print the primary journals and the related parts of Chemical Abstracts. The data is in a fielded format, which is converted to an SGML stream format. The SGML tags used are an extension of AAP Electronic Manuscript Format, enhanced to include the special items such as CAS Registry numbers that are included in the chemistry documents. The character set also must be expanded beyond what AAP provides; ISO codes are used where possible, but additional symbols are necessary. For display purposes, a set of bitmaps suitable for use as X window system fonts are created.
With the intent of providing hypertext-like links between articles on the basis of citations, some special marking of the text is done. Each reference is parsed into journal, volume, and page. If it appears to be a reference to an article in one of our twenty journals, a special code is inserted uniquely identifying the article (consisting of the journal, the volume, the page number, and the first two letters of the senior author's name). The same code is placed at the head of each article. In this way, any full text search system can retrieve the actual articles easily.
The typesetting tapes contain only the textual components of the articles. They must be supplemented with the figures that were printed with the original articles. These are found by analyzing the bitmaps of the scanned pages and looking for graphical material. This process has been described before [Lesk 1990]. and operates briefly as follows. The items being sought are both ``Figures'' and ``Schemes.'' ``Figures'' have numbers and captions; ``Schemes'' do not. They must be sorted out because each is referred to separately in the text; that is, a reference to Scheme 1 may appear before a reference to Figure 1, but the actual graphic for Figure 1 may appear earlier on the page (since, on most pages, the figures appear at the top of the page, while the schemes are in the middle of the columns).
The output of this process is a list of graphical items for each page; it takes about one minute per page on a DEC 5000 to do this. The lists for each page of an article are combined and compared with the list of references to graphics found in the article, and an attempt made to assign the numbers to particular figures and schemes. The article may also refer to tables and equations. The tables can be displayed normally and are taken from the typesetting tape. To simplify the job of the display program, each table is given twice in the Ascii file: once with each cell identified with the AAP tags, and once with the table formatted for constant-width fonts and ready to toss on the display.
Equations are more complex. Again, it is desired to simplify the work of the display program, and so the equations are displayed as bitmaps rather than as a complex typesetting problem. To get these bitmaps, the actual input equation (which is available on the typesetting tape) is converted to eqn, then Postscript, and then to bitmap form. All bitmaps are stored in Tiff Group IV; figures and page images are stored with one image per file, but equations are stored with multiple images per file, one file per article. This is to minimize overhead, since there tend to be many equations in each article which has any, all of them small (in the Journal of Physical Chemistry, for example, the average article with equations has a dozen equations, and a few have over 100 equations; but a fifth of the articles even in this journal have no equations at all).
When all is said and done, the average article is about 7 pages long, and the images of the pages in the article run to 500KB. It contains about 5 figures, and the figures take about 50KB per article. The text of the article is about 40Kbytes, so the text plus images is about 20% of the size of the full page images. The articles range widely in length: some very short errata may be only a few hundred bytes, while a single long article in Chemical Reviews can be over 500KB.
Unfortunately, there are two other large storage demands. First, the text must be processed for full-text retrieval. Depending on what kind of package is used for this purpose, an amount of space ranging from a quarter of the original text size to something comparable to the original text size will be required for the index files. More important, the low resolution of computer screens compared to paper makes it valuable to have alternate resolution versions of each page. In principle, these images could be computed on the fly, but at present that is too slow and so we store alternate versions of each page. The low resolution version presents a number of temporarily painful choices:
Some of these problems are going away as processors and algorithms for image decompression improve. On the latest processors, just becoming available, it is possible to decompress the full size images in 1 second, and thus we should be able to go to on-the-fly creation of the reduced-size images, and tailor them to the user's screen.
Finally, the cost of magnetic storage has meant that at both sites, Cornell and University College London, jukeboxes are being used to store the actual images. At Cornell a WORM jukebox is used; at University College London a magneto-optical jukebox is in use. This introduces additional delays in obtaining images, although not too serious at present.
The purpose of this project is to present alternate ways of accessing chemical information. Several different interfaces have been built. For the purposes of this paper most of the effort will be spent describing the interfaces which were used in a formal experiment. Three ways of getting at information were presented to the users.
Although we have several different interfaces, e.g. the Sceptre interface from OCLC, and the WAIS interface from Thinking Machines, we ran experiments using two particular interfaces, the SuperBook interface for Ascii and a simplistic interface named Pixlook for the images. The interfaces differ in both search engine and in display form, but the primary differences are in the display format. Searching, in both cases, relies on the full text of the articles.
The major difference in search capability is that SuperBook searches for multiple terms as co-occurrences within a paragraph, while Pixlook searches for co-occurrences within an article. For some queries, e.g. liquid crystal, with two common words, paragraph co-occurrence produces a much more manageable list of hits. Other differences include the ability of Pixlook to support fielded searching on eight fields of the article (title, author, author affiliation, abstract, Chemical Abstracts indexing, text, references and captions) while SuperBook has been arranged to support fielded searching only on the title, author, and reference fields. However, searching on the other fields was not common in practice. Pixlook also supports the Boolean searching operations ``and'' and ``or,'' but again these are lightly used, with the alternative coordinate indexing searching being more common.
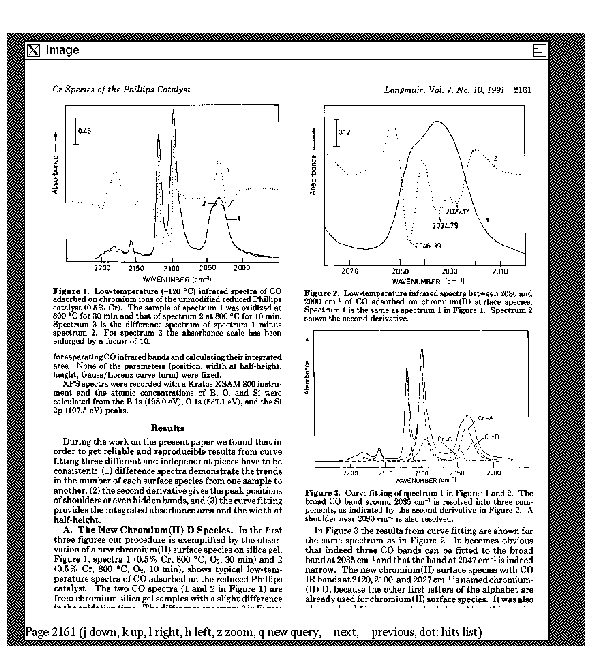
Samples of Pixlook operation are shown in Figures 1-3. Figure 1 shows a simple
search plus the list of matching titles; Figure 2 shows a sample page, and
Figure 3
then shows a sample page image with a ``zoomed'' window enlarging part
of the text.
Note that the Pixlook interface is basically pretty routine:
the displays will normally look just like the printed pages.
Similarly, some SuperBook examples are shown in Figures 4-6.
Figure 4 shows a simple search on ``porphyrin structure'', with highlighted
text words; note the figure and footnote symbols in the right margin.
Figure 5 then shows the footnote popped up, and Figure 6 the figure
popped up. Note that the focus is on the text.
Key aspects of the SuperBook interface include:
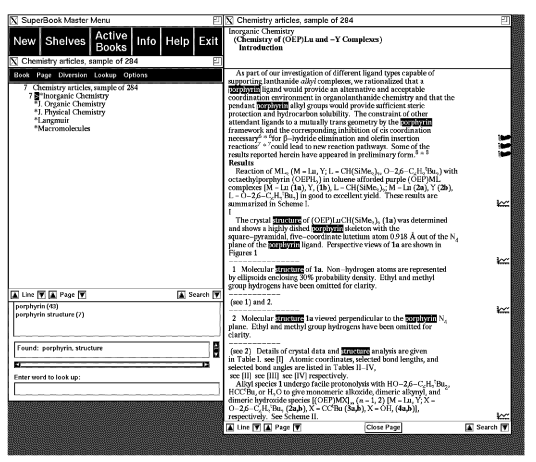


SuperBook has been developed and tested on a wide variety of documents, although originally designed for textbooks. Unlike normal hypertext systems, it always maintains the text as a linear sequence, and so the user always can have a sense of position in the document. This position is shown both in the table of contents window and at the top of the text window, where the hierarchical headings are shown leading down to the place in the text represented in the window. Thus, SuperBook is not as well adapted as it might be to this collection, which consists of a large number of individual articles with weak relationships between them. As a result, even though it performed fairly well in our experiments, it can probably be tuned to do better on this particular collection.
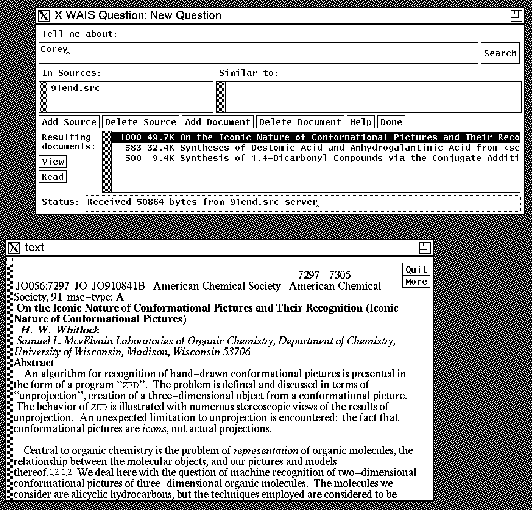
As mentioned, other interfaces are also available. Figure 7 shows the
WAIS interface (from Brewster Kahle of Thinking Machines) which can display
both the Ascii text (but with no structure) or the full page images.
 All the interfaces run on the X windows system and can be accessed remotely
over the Internet.
All the interfaces run on the X windows system and can be accessed remotely
over the Internet.
We evaluated the different interfaces by experiments carried out by chemistry students at Cornell University. The experiments were based on a set of 1000 articles (the contents of Journal of the American Chemical Society for the first twelve issues of 1988). Three dozen students were divided into three groups: 12 were given the journal issues on paper; 12 were given Pixlook; and 12 had SuperBook. All of these groups were asked to do five different kinds of tasks, made by two chemistry professors. They were all given roughly half an hour of training, and then asked to do tasks for three sessions of two hours each.
The five different kinds of tasks represent a spectrum of difficulty. The table below shows the tasks.
| Task | Goal |
| Citation | Find a particular fact in a known article |
| Search | Find a particular fact in an unknown article |
| Browsing | Scan an issue for any of 8 topics. |
| Essay | Write paragraph on a topic. |
| Transformation | Find analogy to a structural transformation. |
The details of the results have been given by [Egan 1991], so only a summary will be presented here.
In general, there was no trade-off between speed and accuracy. Errors came from difficulty of doing the task, not from rushing through it. Students were still learning how to do some tasks, such as the browsing task, on the third session of the experiment (i.e. after more than 4 hours of experience).
We also gathered the comments of the students using the system, who generally liked it but had many specific suggestions, often oriented towards making the systems easier to use. For example, requiring the ampersand instead of the word AND for specifying Boolean combinations did not seem friendly. It is difficult to scan long articles in image format, and some way of indicating where specific words can be found would be desirable (this is also quite difficult, requiring guessing on the basis of the article length).
We also talked to a number of chemists who were trying experimental versions of the system. Perhaps because these were the most motivated of the chemists, they tended to be very interested in information retrieval systems and thus to be familiar with the online systems that already exist. Their comments were less focussed on useability and more on functionality. They asked, for example, for the ability to save searches, and to search on CA substance index terms. They also asked for some new facilities, for example the ability to quickly move from an article to an article that it cites or that cites it. And they wanted better ways of downloading information so that they could assemble their own databases from tables in the articles they found.
Observation of the actual performance of the students on the tasks also leads to suggestions for improving the systems. For example, the students got into trouble doing the citation task with SuperBook when they wandered out of the article they were supposed to be reading. Unlike a paper journal, it is possible in the computer files to jump a thousand pages forward without realizing it. We can and have modified the interface to make it more obvious which article is being read, so that future users will know what to do.
Critics of electronic information delivery sometimes mention the importance of serendipity, so we tried to measure it. The students doing the browsing task had been given an issue of the journal, and a list of eight topics, and asked to list the ones which appeared in the issue. The students could either simply flip through the issue (as most students with the paper copy did) or try to search for the eight topics (as most students with SuperBook did). When they were done, the issue was taken away, and then they were given another list of topics to judge, testing their memory of what they noticed about the issue besides what they were looking for. The average performance on this second task was 60-65% correct, with no significant difference between those with paper and those with the electronic forms. Thus, serendipity was as high with computer access to material as with paper, refuting the fears of many about electronic libraries. Note that in no case is this performance very good: since the students would have achieved 4/8 right guessing at random, reaching 5/8 is not great (although it is statistically significant).
Perhaps most interesting is the importance of graphics to the various
chemists. It is possible that the interface they would like most would
be one in which the articles were represented by images, with the text
being hidden under icons. For example, we put together such a search system
as shown in Figure 8, which we referred to as the ``comic book'' version of the
Journal of the American Chemical Society.
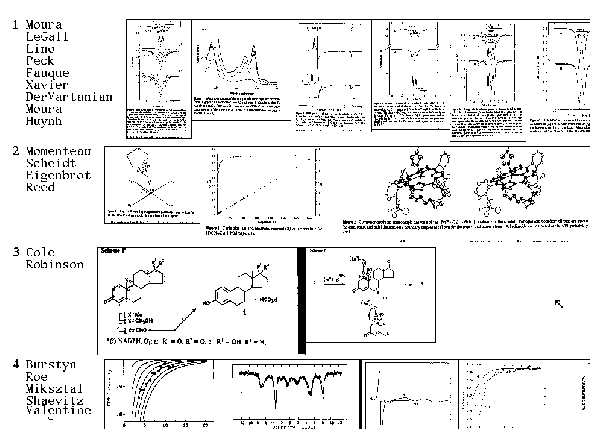 Although the difficulty
of searching pictures makes entirely image-based interfaces hard to build,
we should look more carefully at interface designs that rely on presenting
large amounts of visual material very rapidly, rather than slow, precise
access to particular sentences. Most information needs that scholars have
are relatively vague, and some combination of browsing and searching is
more typical than the very focussed searching that information systems
are often designed to meet.
Although the difficulty
of searching pictures makes entirely image-based interfaces hard to build,
we should look more carefully at interface designs that rely on presenting
large amounts of visual material very rapidly, rather than slow, precise
access to particular sentences. Most information needs that scholars have
are relatively vague, and some combination of browsing and searching is
more typical than the very focussed searching that information systems
are often designed to meet.
Chemists use journal articles in many ways, from finding the address of an author to just looking for something interesting. Some chemists like to read words; others like to look at structural diagrams; some probably even like reading mathematical equations. Any system which serves them, whether based on paper or on electronics, must cater to a very wide spectrum of needs. The lessons we think we have learned, and are trying to apply in our software design, are:
We were not able to settle whether image or ascii interfaces are preferred. The ascii text is needed for doing searching, but it seems that people can read the image text at comparable rates; apparently the familiarity of the format and the immediate visibility of the graphics compensates for the inadequate resolution of the computer screens.
But the main message is that performance overall was as good reading on screen as on paper, and better searching on screen. Either image or ascii display will do, but computer systems can compete with paper for performing chemical tasks.
This project is a collaboration led by Cornell University and including, in addition to Bellcore, the American Chemical Society, Chemical Abstracts Service, OCLC and University College London. Among the people who have done much of the work on the overall project are Jan Olsen, Howard Curtis, and Rich Entlich of the Albert Mann Library, Cornell University; Lorrin Garson of the American Chemical Society; Jim Lundeen and Lorraine Normore of Chemical Abstracts Service; Martin Dillon, Martha Lindeman, Eric Sigman, Mark Bendig and J. Charles Crabb of OCLC; and David Golds and Peter Kirstein of University College London. The collaborators are grateful for the support of Apple Computers, Digital Equipment Corporation, Springer-Verlag, Sun Microsystems Inc., and Sony Corporation of America.
[Egan 1991]. D.E. Egan, M.D. Lesk, R.D. Ketchum, C.C. Lochbaum, J.R. Remde, M. Littman, and T.K. Landauer; "Hypertext for the electronic library? CORE Sample Results," Proceedings of Hypertext 91, San Antonio, Texas (1991).
[Gordon 1988]. S. Gordon, J. Gustavel, J. Moore, and J. Haney; "The effects of hypertext on reader knowledge representation," Proc. Human Factors Society 32nd Annual Meeting pp. 296-300, Santa Monica (1988).
[Kaindl 1992]. Hermann Kaindl, and Holger Ziegler; "HIS \- An Information System about Hypertext on Hypertext," SIGLINK Newsletter 1 pp. 1-8 (March 1992).
[Lesk 1990.]. M. E. Lesk; "Full Text Retrieval with Graphics," NATO AGARD Conference Preprint No. 487, ``Bridging the Communication Gap'' pp. 5-1 to 5-7, Trondheim, Norway (Sept. 5-6, 1990.).
[Lesk 1991]. M. E. Lesk; "The CORE Electronic Chemistry Library," Proc. 14th ACM SIGIR Conference pp. 93-112, Chicago (October 13-16, 1991).
[Marchionini 1988]. G. Marchionini, Marchionini88, and B. Schneiderman; "Finding facts vs. browsing knowledge in hypertext systems," IEEE Computer 21 pp. 70-80 (1988).
[McKnight ]. C. McKnight, A. Dillon, and J. Richardson; "A comparison of linear and hypertext formats in information retrieval," Proc. Hypertext II, York, England