Making a Digital Library: The Contents of the CORE Project
Richard Entlich
Cornell University
Ithaca, NY 14850
Lorrin Garson
American Chemical Society
Washington, DC 20036
Michael Lesk
Bellcore
Morristown, NJ 07960
Lorraine Normore
Chemical Abstracts Service
Columbus, Ohio 43210
Jan Olsen
Cornell University
Ithaca, NY 14850
Stuart Weibel
OCLC
Dublin, OH 43017
Abstract
The CORE (Chemical Online Retrieval
Experiment) project is a library of primary journal articles in chemistry.
Any library has an inside and an outside; in this paper we describe the
inside of the library, the methods for building the system and accumulating
the database. A later paper will describe the outside (user experiences).
Among electronic library projects, the CORE project is unusual
in that it has both ASCII derived from typesetting and
image data for all its pages,
and among experimental electronic library projects, it is unusually large.
We describe here (a) the processes of scanning and analyzing about 400,000
pages of primary journal material; (b) the conversion of a similar amount
of textual database material; (c) the linking of these two data sources
and the indexing of the text material.
1. Introduction.
Rapid evolution of telecommunication networks is feeding the demand
for document delivery to the desktop.
[McKnight 1993].
[Birmingham 1994].
[Kibbey 1989].
[Lynch 1989].
[Schatz 1994].
The CORE Project is a model for
the conversion of large text and graphics collections to an electronic
format that will serve the document delivery needs of scholars in a
distributed networking environment. As such it provides a
realistic laboratory environment in which to investigate the
technological problems associated with full text retrieval and
delivery.
The CORE project has five objectives;
-
Define a suitable architecture for delivery of full text information in
a distributed networking environment with heterogeneous workstations.
-
Convert and mount a critical mass of chemistry journal data in a
database format suitable for effective retrieval and display.
-
Study the elements of full text interface functionality necessary
to serve the needs of scholars in a network document delivery
environment.
-
Advance the understanding of suitable document markup for electronic
full text databases.
-
Investigate information retrieval questions germane to the coming
era of full text delivery.
The most important property of an electronic library, just as of
a paper library, is its collection.
[Miksa 1994].
Selection of quality material is the first important requirement;
junk, even presented with a lot of glitz, is still junk.
Interviews with Cornell chemists pointed to primary journals as their
most important resource; fortunately, the CORE project has
been able to obtain its material from the American Chemical Society (ACS).
ACS publishes the chemistry journals of
highest prestige in the United States, and its journals are a key
resource for chemical research. We use the twenty primary journals
being published at the start of the project; these are
Accounts of Chemical Research,
Analytical Chemistry,
Biochemistry,
Chemistry of Materials,
Chemical Research in Toxicology,
Chemical Reviews,
Energy and Fuels,
Environmental Science & Technology,
Inorganic Chemistry,
Industrial & Engineering Chemistry,
J. Agricultural and Food Chemistry,
J. American Chemical Society,
J. Chemical Engineering Data,
J. Chemical Information & Computer Science,
J. Medicinal Chemistry,
J. Organic Chemistry,
J. Physical Chemistry,
Langmuir,
Macromolecules,
and
Organometallics.
The users of our library were students, faculty and employees at Cornell
University, in the chemistry department and in many
related departments (chemical engineering, materials science, and so on).
Their desktop equipment ranges from PCs
and Macintoshes to high-powered Unix workstations. Connectivity,
originally, was also varied. In an effort to be able to rely
on some minimal capabilities, we (a) accelerated the deployment of
Ethernet in the chemistry department, and (b) asked all
users to have at least 900x700 pixel screens. Some of our data
have also been made available (with permission of ACS, of course) to
University College London where related experiments have been done,
including testing different levels of network access and terminal
equipment [Kirstein 1995].
Even electronic libraries need librarians. In our case, the
staff of the Albert Mann Library at Cornell has had to provide
not only program installation, but also user counseling and
advice. This has required considerable technical consultation about
X-windows idiosyncracies, e.g. security procedures, and other setup issues.
The CORE system is built on a Unix-based client-server architecture
that runs on the departmental Ethernet at the Cornell University
Chemistry Department, connected to a server at the Albert Mann Library.
Figure 1 illustrates the components of the
system, showing the flow of information from the providers,
the American Chemical Society (ACS) and Chemical Abstracts Service (CAS),
to the files, to OCLC's Newton search engine, and then to the users.
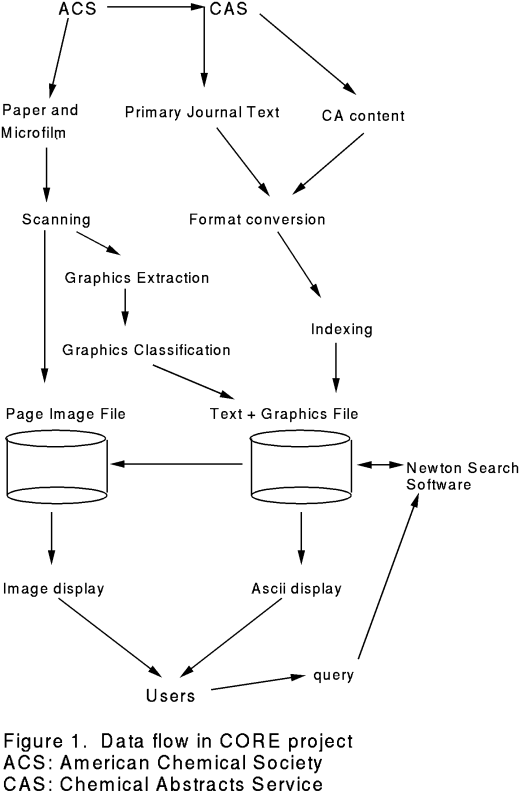
The searchable text and extracted graphics reside on
magnetic storage for rapid retrieval. OCLC (the Online Computer
Library Center) has provided the Newton retrieval system,
which supports a variety of OCLC's database and reference products, and which
serves as the database engine for both of the user interfaces employed
in the project. Newton is a client-server database system that
provides substantial flexibility from the standpoint of data design and
from a networking point of view.
Accumulating the
database has taken more time and money than coding the
viewing software. At the time of writing, our main server has
a SONY jukebox with 150 GB of WORM (write-once-read-many)
storage plus about 75 GB of
conventional magnetic disk storage. All of this has to cope
with about 400,000 page images, in two sizes, plus about 4 GB of
text, another 6 GB of graphics data, and 7 GB of indexing.
Some electronic library projects are text-based and some image-based;
The CORE project is unique in having both information sources,
and being able to compare the results. We have used
the database accumulated by the American Chemical Society as part
of their publication process,
[Love 1986].
and also have scanned the
journal pages. Users can access either format.
The size of the system is summarized in Table 1; image pages
run about 100Kbytes each.
| Size of CORE data |
| Item | Count |
| Pages (complete) | 428,819 |
| Articles | 81,635 |
| Megabytes of text | 4,360.787 |
| Megabytes of text+indexing | 11,097.770 |
| Extracted graphics | 399,606 |
| Disk space for graphics | 6GB |
The text and index are not compressed; compared to the amount of
space required for the images, it would not reduce the storage
requirement enough to be worth the complexity and delays in access.
2. Data Acquisition \- Scanning
The image data are obtained both by scanning paper and scanning film.
Paper scanning is relatively straightforward and routine; an
Improvision scanner (based on a Ricoh paper handling mechanism) is
connected to a Sun workstation. It can scan about 20 pages a minute,
and costs about $13,000. An operator fed most of the sheets one at
a time since the ACS paper is fairly thin. The output is 300 dpi,
one bit per pixel. The two sides of each sheet are scanned in separate
passes, and the page numbers sorted out later. Quality is very high except
for some skew, arising either from improper trimming of the journals or
misfeeding of the paper. We scan at one bit
per pixel since virtually all the pages contain only straightforward text
and line drawings. About 1% of the pages contain a photograph and 0.1% of
the pages may contain color; these suffer significant degradation.
Film scanning is more complicated. Some was done on a Mekel
scanner at Bellcore, but the size of the job
caused us to contract out the scanning, to two
different vendors. Microfilm scanning is a less mature market
and there have been problems with
extra dots introduced into the scans, and with stuttering (scanning
the same frame twice). Although most of these basic problems have
been solved, the quality of scanning
from microfilm is still much lower than from paper.
An additional complexity in microfilm scanning was the presence
of ``supplementary pages'' on the film which have to
be removed. When an article begins in the middle of a page, the
supplementary pages are inserted by cutting the page and filming
each half separately.
Although one can sort this out fairly well by using the page density,
counting the number of columns in the image,
or trying to OCR the page numbers, all of these have problems, and
in the end we relied on manual identification and clean-up.
Maintaining quality was a constant effort;
scanning of even 200 dpi resolution from the microfilm was considered
inadequate and we moved to 300 dpi for both paper and film.
Quality was a particular problem with reprinting, which
needs better images than
screen display, as the users are familiar
with the high quality of the normal printed journals, and would like
our scanned pages to reprint at an equivalent level; they have fewer
a priori expectations of screen images.
Although we have discouraged users who had minimal (640x480) screens,
even the larger screens (1152x900) are inadequate for a full
page at 300 dpi. We eventually decided to store all images twice, once
in full resolution (usually 2560x3328) and once in a 3X reduced version
(856x1109), with grey-scale added. Computing grey scale from the
full size images to the smaller images lets us improve readability
(effectively anti-aliasing). It also takes advantage of the fact that
most of the users who have the smallest screens, and who must depend on
the small-size images, also have color displays.
Displaying also involves response time issues. Where should operations
such as scrolling and Tiff decompression take place? In general, we
have been limited by X considerations: we do those operations that can
be specified in the window manager (e.g. scrolling) on the user machine,
and we do Tiff decompression on the server. This means
that full decompressed images must be sent to the user machine from the
server, consuming both network bandwidth and memory on the user machine.
As mentioned before, many of the users with small screens also have color
displays, and can thus use the grey-scale information in the reduced
bitmaps to improve legibility; unfortunately
these machines also, in practice, have the slowest CPUs.
Response time also depends on image storage. One consequence
of the size of our files (about 100 GB total)
is that many of our page images are
out on the WORM jukebox. This introduces an unavoidable delay into
the retrieval of full page images; fortunately the average time taken
to read a page is about 90 seconds, so the throughput for those reading
articles thoroughly does not have to
be very high. In an effort to minimize the jukebox delays, we have
implemented a simple read-ahead cache; the program fetches the first
five pages each time it gets a new article from the jukebox; in 5000
page displays, the page requested is within five pages 54% of the time.
Nevertheless, for browsers faster response would be desirable.
3. Figure Extraction
Although the typesetting and database creation process of the American
Chemical Society provides the complete text of the articles, it does not
give us the graphic elements of the pages. There is an average of one
illustration per page, and about a quarter of the average
page is not text (measured in square inches). Half the pages, however,
have no graphics at all. The illustrations are essential to the
understanding of the article; online full-text systems which leave out
the illustrations are often used merely as finding aids, rather than
as replacements for the paper. Our only route to these figures is to
find them in the page images. Since we wish to find 399,000 figures and
schemes in 80,000 articles with 428,000 page images, we have to do this
automatically.
There are four kinds of non-text elements in the pages: tables,
equations, figures and schemes.
The equations and the tables are in the ACS-provided data, so that we
only need to find the figures and the schemes in the page images.
Both figures and schemes are visually similar: they are both line
drawings, which in the case of figures may include chemical structures,
spectrograms, diagrams of equipment, and so on; schemes are usually
chemical structures. They must be sorted out, however, since the
schemes and figures can be moved past each other in the course of
typesetting: that is, scheme 1 may be referred to in the article before
figure 1, but may appear after it on the page. Figures are always at
either the top or bottom of the page, while schemes can appear in the
middle of a text column (but often appear at the edge of a page as well).
Despite an attempt to avoid OCR in general, the only really reliable
way of sorting figures from schemes is to find the caption by looking for
the word ``Figure'' as a bitmap.
Page segmentation is a well-studied problem,
[Fletcher 1987].
[Wang 1989].
[Srihari 1994].
but often the previous
work has involved halftones or other material which is locally different
from text printing. Nearly all our illustrations are
line drawings; and there is a continuum between some
tables or chemical equations and some figures or schemes.
We therefore wrote our own programs to deal with graphics
extraction, based on the regularity of lines in normal text.
Figure 2 shows a part of a journal column,
and Figure 3 plots the number of black bits per scanline.
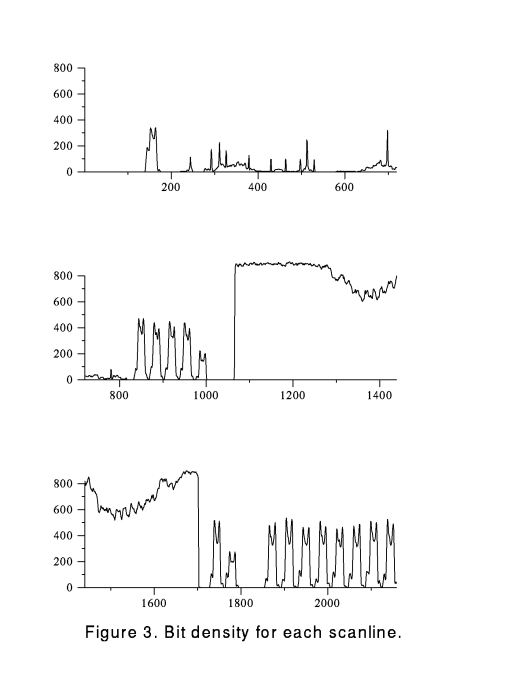
The column begins with a normal figure (a line drawing), which runs from
scanline 200 to 800, with irregular low values of bits per scanline (the
bump at 150 is the heading line on the page).
A five-line caption follows, the five regular bumps from scanline 800 to 1000.
There follows an unusual
dark figure (1100 to 1700), with a two-line
caption (1700 to 1800) The remainder of the column (1800 on)
is lines of text, and regular bumps appear in the plot.
The regularity of this density plot of ordinary
typeset text separates it from the irregular density characteristic of
figures. For speed, we use only
overall measures of bit density, not exact character matching (except
for the word ``Figure'' as earlier mentioned).
The first step in graphics extraction is to align the page accurately
on the axes. As mentioned before, the cutting or scanning of the pages can
introduce skew. Correcting this is not trivial because the top
or bottom of the page may include a large figure with white
space around it. We find the left edge of
each scanline, and find the line down the page pushed
as closely as possible up against the text to find the skew.
The page must
be within one degree of correct orientation for the rest of the software
to work. Another method for deskewing was discussed by Baird.
[Baird 1987].
After deskewing, we break the page into regions of single and double
column. Normally ACS pages are double column, but there may be one region
of full-width material, either the title/author block for an article
beginning on the page, or a full-width figure or table. The program
looks at the vertical density plot (how many black bits in each
vertical stripe down the page, taken in thirds),
identifies the column boundaries, and locates the
transitions between double column and full-width areas. Eventually, the page
is cut into at most five regions (two columns at the top,
two columns at the bottom and one
full-width section).
Each region is then scanned for figure captions, using exact bitmap
matching for the word ``Figure'' (since the journals use different
typefaces, different masks are used for different journals). Each region
also has its horizontal densities computed, and the program sets out
to compute the autocorrelation function, that is for density d(i)
on scanline i,
F(t) = sum of d(i) × d(i+t)
summed over a range of about a third of the page at the bottom (most
likely to be straight text).
This function will be maximized at the value of t corresponding
to the line-spacing. Given the line spacing, it is then computed
for the whole page, over a range of about 5 line spacings, and
a threshold used to select which parts of the page are graphics.
Figure 4 shows a sample column with the density function plotted just to
the left of the text and the autocorrelation function at the far left.
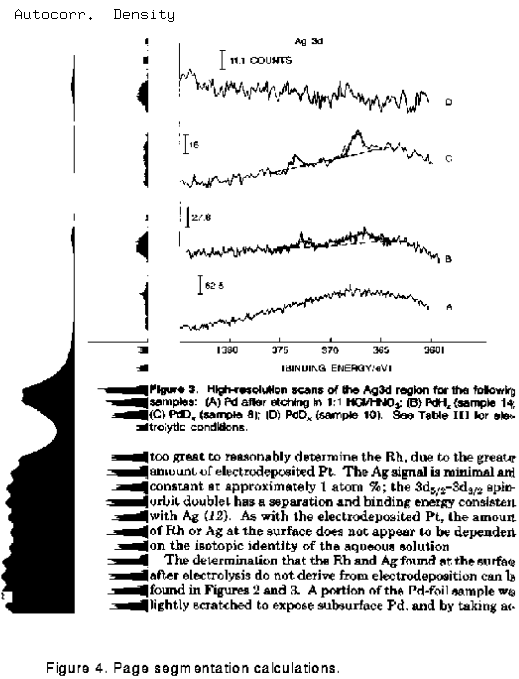
Figure 5 shows the result of the whole process: the figures and
schemes have been spotted correctly by the program and marked out (using
different boxing to represent the figures and schemes separately).

4. Data Acquisition \- ASCII
The data which comes in ASCII is provided in a formatted representation
by ACS.* In this format, numerical field labels encode a variety of
data types: ISSN, title, sentences, subheads, and the like. Separately,
a special character set is used. In the ACS format subscripts,
superscripts, and font shifts are encoded in the character set.
ACS also uses various extra kinds of data representation: some footnote
references are marked with ##-delimited strings, and equations have
another entire formatting system in the text. ACS was one of the leaders
in computer typesetting of primary journals more than twenty years ago,
and this format, although not following the recent SGML (standard
generalized markup language) philosophy, has
been effective for their database maintenance.
* Chemical Abstracts Service (CAS), which is a division of the American Chemical Society, provides
composition services to the Publications Division--the publisher of the
primary journals. ACS keeps the database accurate (there are no pasted-in
corrections) and linked to the actual journal page numbers.
For the the CORE project, CAS provided the corresponding
index data (terms and registry numbers) for each article so that users could
also retrieve information by searching Chemical Abstracts data.
The ACS's proprietary data markup represents the structure of the
data, unlike computerized typographic systems that have become commonplace
in the publishing industry as a method of expressing the structure and
layout of documents.
To produce a single portable database which
conforms to current standards
and to simplify our software construction problems, we adjusted the ACS's
proprietary data markup by changing to SGML.
SGML is an ISO standard for the
description of text in machine readable form, and converting to it
helps feed into software systems that can mount
databases of broad scope and diverse sources.
[Coombs 1987].
CORE text is being translated
by Bellcore from ACS's structured files into SGML. The latter marked-up
version of the text is then used to build the Newton database that will serve
the various user interfaces in the project.
Markup of this database is critical: it
defines the structure of the database and differentiates
document elements for display purposes.
SGML tagging permits interfaces to search for specific document components.
The use of SGML greatly enhances the flexibility of a database, but
defining the structure of the database in advance requires a thorough
understanding of the functionality that the user interface will
require. A major activity in the CORE project during 1993 has
been a collaborative, iterative refinement of the database model such
that the full CORE database could serve the needs identified in previous
user studies as well as enhancements that have been added. That a
single database is to serve all of the user interfaces adds further to
the complexity of this design process.
An SGML document consists of text that is marked up with descriptive
tags that specify the function of a given element within the document.
As a formal language construct, an SGML document can be parsed against
a Document Type Definition (DTD) that unambiguously defines what
elements are allowed and where in the document they can (or must)
occur. This formalized map of article structure allows the user
interface design to be uncoupled from the underlying database system,
an important step toward interoperability.
Conversion to SGML produces some complexity. For example, in the
character representation used for the ACS publication system
font changes and baseline position are
handled in the character set, rather than
with tags: that is, the same mechanism that would change an ``a'' into
a ``b'' changes an italic ``a'' into a bold ``a'' or a
superscripted ``a.'' We must convert this mechanism into SGML tags, and make
some reasonable decisions about which tags to use and where to use
them (e.g. an author name
in italics should be tagged as an author, not just as
an italic string).
SGML by itself does not define the semantics of the document under
description. We began with the
AAP Electronic Manuscript Standard (EMS),
but it does not contain enough
[Publishers 1987].
tags for some of the more complex parts of the CAS format. For example,
there are super-superscripts, tables of definitions of symbols, and a complex
set of subfields within the Chemical Abstracts subject indexing. We have
defined extensions to the EMS to provide new tags for these complex data.
Even many years after CAS defined their database representations, the official
standards organizations still have not agreed on how to formulate such
complex material.
There are currently some 85 tags that are used to identify the function
of text elements in the data, including not only
the usual article titles, authors,
author affiliations, section headings, bibliographic elements, but also the
abstracting and indexing elements (especially important in a field such
as chemistry where there is an unusual systematized nomenclature for compounds
that is very frequently used and important for retrieval).
In addition we must include the pointers
to several different kinds of graphic elements.
On the other hand, there are aspects of the EMS we do not use: the
three different ways to specify Greek letters reinforces
the old saw ``the good thing about standards is that
they provide so many choices,'' and we have used only one.
Tables and equations are handled from the ASCII data, to avoid
dependence on bitmap-clipping whenever possible. Tables are
converted to both monospaced layout and SGML. The monospaced
layout simplifies final presentation; the SGML version was provided
in case future development produced a desire to write a proper table
formatting program. Tables are particularly hard to manage on a variety
of screens: it would be necessary to determine character widths on the
final display unit, and adjust the table accordingly. It simplified
matters considerably to provide a monospaced version.
Equations are more complex. No monospaced version will be legible.
We felt there were three choices: (a) implement enough of Postscript
to typeset equations, (b) produce an equivalent of Postscript in some
other text display format we designed, or (c) send bitmaps to the workstation.
Choice (b) seems silly, and choice (a) seemed like too much effort for
the benefit. So we opted for choice (c), since the interface software
must support bitmap display in any case (for figures). We take the
ACS equation format, translate it to Unix ``eqn'' format, run it through
the Unix typesetting tools to get bitmaps, and then treat these as if
they had been scanned. The major disadvantage of this process is that
one can not click-search on text within equations, but there is rarely
anything in an equation which makes a sensible search term.
Two particular features of AAP/EMS SGML were so inconvenient we avoided them.
AAP/EMS relies on nesting to disambiguate certain kinds of tags: e.g.,
the title of an article cited in a bibliography gets the same tag
as the title of the main work. We found it much easier to define separate tags
for titles, authors and so on within a bibliography. Also, AAP/EMS uses
character escapes distinguished only by case, e.g. `&Agr;' and `&agr;' for upper
and lower case Greek respectively. We use double
letters instead to be compatible with searching tools that do not make
case distinctions. Since the Greek alphabet is used largely for
mathematical or chemical symbols, rather than to include text written
in the Greek language, users need to be able to search for the Greek letters
in upper or lower case.
Among the more complex aspects of conversion
are linking up bibliographic references
in the text to their citations. Some of the journals mark this
unambiguously in the data input, others use superscript numbers,
others italic numbers in parentheses, and others the form
``(Smith, 1990)'' (and one journal changed its style during
the time period of our collection). The program makes various guesses
to try to decide when a superscript is a mathematical exponentiation
or chemical atomic number and when it is a footnote.
Formatting text for online display is a complex tug-of-war between
the user, the system and the platform. In systems where all users
have one kind of workstation, under the control of the system
administrator, this can be fairly straightforward. In our context,
users have a variety of machines and run a variety of software, and
we can not realistically tell them to change.
Rather than attempt to describe each user display terminal
and configuration, and write typesetting software for every one,
we used X as our display standard, running
emulators on the Macintosh. Even X, unfortunately, is far from
standard: each terminal may (and often does) have different font sets
installed, and we were forced to install some standard fonts on the
terminals plus a font of our own to provide many
chemical and mathematical symbols. To save font design effort,
some overstrike approximations are used for accented characters not found
in standard Adobe layouts.
Display management raises control issues. Who should
set up the arrangement of windows on the screen \- the display software
or the user? Even within the group of authors of this paper, there is
no agreement; in practice this means that some users are willing to
place every window separately in order to maintain total control of
screen content. The software must thus permit and tolerate this, including
people who make certain windows either much smaller or much larger than
the original program designer anticipated. The strategy of grabbing one
large window and then subdividing it was rejected by some users.
5. Database Design and Use
Database design and user interface functionality are necessarily
closely coupled: effective database design must be informed by the
desired interface functionality and interface functionality is
constrained by the practical limitations of database structure.
On the other hand, we wished to compare the various interfaces,
without duplicating the indexing files if possible.
Usability has been the prime concern in all interface design work.
Three interfaces were coded, two of which are being used in the final
experiments. Both of these interfaces take advantage of the X-Windows
windowing system. X-Windows has several advantages that make it the
system of choice for interface development in a distributed network
environment. Its most important characteristic is that it provides the
ability to create a single application that will run on a variety of
hardware platforms without machine-specific dependencies. X-Windows
servers are available for virtually all PCs and workstations; the
server manages all display functions and hence frees the application
from machine dependencies. As a client-server application, the use of
X-Windows also simplifies distributed networked applications. The user
interface code, the database search engine, and the user's display can
be running on different machines as appropriate to the environment,
including at geographically distant sites.
The page layout of a well designed publication is important to ease of
assimilation and comprehension by the reader. This is one of the areas
where computer interfaces fail; it is difficult to convey on a
computer display the richness of page layout and data markup that is
taken for granted on a printed page.
[Kling 1994].
Figure 6 shows OCLC's SCEPTER (SCientific Electronic Publishing
and TExt Retrieval) interface.
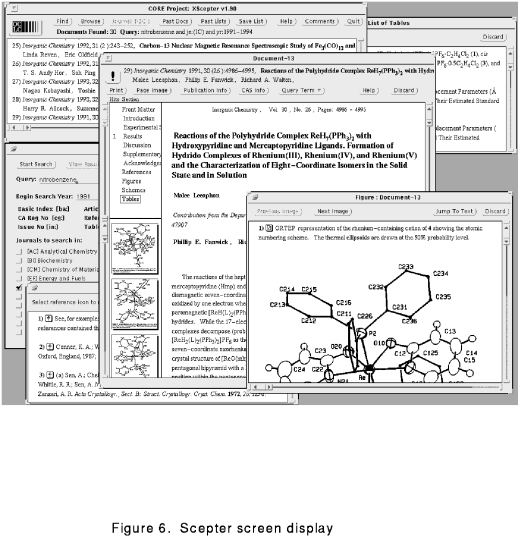
The screen display is formatted ``on the
fly'' based on the SGML markup in the database. The user interface
interprets the markup in the data it retrieves and lays out the screen
display according to a set of display rules. There has been no attempt
to emulate the printed page in style, but rather to display the data in
a pleasing, logical manner that will enhance users' ability to
effectively identify relevant articles and information, either for
reading on the display or to print for subsequent usage.
The inherently greater flexibility of displaying text on a screen is
both boon and bane. On the one hand, the user has the flexibility to
navigate in the database in new ways, following links from article to
article, or browsing lists of related articles, or figures. The power
of hypertext-style searching in a large collection should be an
important tool for scholars.
On the other hand, providing intuitive interfaces that are both
powerful and easy to learn is a poorly understood art that will evolve
with experience. Users can fill a screen with a bewildering array of
windows that can be difficult to arrange sensibly, especially given the
limited screen real estate of current display technology.
The basic metaphor for the SCEPTER user interface is to provide the
user with a variety of ways to construct lists of relevant documents for subsequent viewing:
-
browsing indexes (a dozen or more specific indexes will facilitate the
construction of highly specific queries),
-
searching for known terms (full boolean capabilities are available to
support query construction),
-
using date and journal restrictors to limit queries.
Documents may then be loaded into the document viewer portion of the
program. The viewer includes a table of contents of the article,
always visible on the left-hand side of the "page" display. This table
of contents is built dynamically from the headings and fixed lists
(figures, tables, and references) for each article as retrieved. The
user can display any of these sections by selecting the table of
contents entry with the mouse.
Small icon buttons are visible within the text; each of these icons
represents a link to a particular type of data: a citation, footnote,
equation, table, or figure. Selecting a particular icon brings up a
separate window containing the particular data item represented by that
icon.
Having displayed such a figure or reference, it is possible to cycle
through "previous" and "next" elements of that series, as well as to
return to the place in the text where such items occur.
It is also possible to jump to a referenced article if that article is
represented in the database. This ability to follow citation links
through a large database is one of the more powerful features of an
electronic document database that will save scholars a great deal of
effort.
Another interface is an image interface, now called Pixlook, which
displays the scanned images directly, and only has to print the titles
and authors from the ASCII text. Pixlook is written using
John Ousterhout's Tk/Tcl package,
[Ousterhout 1994].
supplemented with C programs to
process our various page image formats. A sample display is shown in
Figure 7.

It only displays the images of retrieved pages, similarly
to systems such as RightPages
[Hoffman 1993].
or Adonis.
[Stern 1990].
Originally, this program
had its own search system, which relied on an inverted file that
pointed to approximate locations in the full file; this did not support
word adjacency searches, but it was very compact. Subsequently, we converted
to use the same search engine as Scepter. Pixlook offers two basic
modes of choosing what to read:
-
the user may browse through lists of article titles;
-
the user may search on words or Booleans;
and only one way to view the result, namely to look at the page images.
In the browsing mode, users click through menus of journals, years,
and issues to get to the list of authors and titles in any one issue.
Clicking on any line in the author-title display brings up the first
page of the corresponding article. In the searching mode, the user
types a search request into the lookup window, and the system returns
the authors and titles of the hits. If there are a great many hits,
the system gives the first fifty, an estimate of how long it will
take to find the rest, and a button to ask for them. Again, clicking
on an author-title line brings up the first page of the article.
Each page display starts out in low-resolution (100 dpi equivalent,
2 bits per pixel on displays which can support grey-scale or color).
A set of buttons at the top control:
-
moving to or from a full-resolution 300 dpi image of the page (only a
small part of which will fit on the screen, of course);
-
moving to the next or previous article in the list from which
this one was picked;
-
requesting a paper printout of the article;
-
obtaining help or closing the window.
Scroll bars at the right and bottom move around a page
image which does not fit on the screen (always the case
for enlarged 300 dpi images), and a ``scrollbar'' at the top
moves from page to page within the article (in discrete
pages only). This last bar also gives the user a cue as
to how many pages there are in this article.
We have also, in some experiments, used a version of
Bellcore's SuperBook
[Egan 1989].
interface for evaluation. In an earlier paper we presented the
results of this work, which demonstrated the enormous advantages of
computer systems for any kind of application involving searching.
[Egan 1991].
SuperBook is a text display system with a strong linear model of the
documents, which must be organized into a hierarchy. Unlike Pixlook
and Scepter, it does not provide bitmaps except for graphics, and
its searching system offers less flexibility than Scepter. For
these reasons it was not used in the final experiments.
6. Newton search engine
The Newton search engine was designed and implemented at OCLC for
access to tree structured data of arbitrary complexity. The search
engine may be used as the basis of a fully functional information
retrieval system for structured textual data and images. Text in the
CORE data is marked up in SGML, but any formal markup language can be
used to define the process for designing and building the search engine
database.
Searching/Browsing Capabilities.
Newton provides extensive searching capabilities including keyword and
full Boolean retrieval as well as proximity and field restriction
retrieval. Range searching, truncation, and wild card searching are
fully supported. All database indexes are browsable.
Because there is a well defined application programmer's interface to
Newton, a variety of user interfaces may be built to use the search
engine. This allowed us to support both Bellcore's Pixlook and OCLC's
SCEPTER with a single database.
Database Preparation.
One of the strengths of Newton is the power and flexibility of the
indexing system. The indexing programs are driven by a database
description file. This file contains information that describes the
structure of the input records and the rules for indexing each of the
fields of the record. The language in the database description file is
compiled by the indexing programs into tables that are stored in the
database files themselves and are used to drive the initial loading of
data and all subsequent updates and additions to the database.
Newton recognizes both physical and logical database views. A logical
database can grow quite large, on the order of hundreds of millions of
terms and millions of records. A logical database is a special way of
grouping smaller, and hence more manageable, physical database
partitions so that they appear as a single unit from the searcher's
point of view. This allows the database to grow to an almost limitless
size through the simple expedient of adding additional partitions.
Various retrieval problems, many of them familiar in information
retrieval, have turned up during our testing.
-
There is a large range of user expertise, and
many users don't know much about fielded Boolean searching.
Scepter relies heavily on menus to select journals or years to search
to avoid forcing the users to learn how to write complex search
language expressions.
-
The database is very large, and it is easy to write a query which retrieves
a staggering number of documents. We retrieve the
first fifty documents for such queries and suggest that the user rephrase the
query.
Another possibility would be to use relevance feedback to do the
rephrasing automatically.
7. Summary
After several years, what have we learned from the CORE project about
building large digital library systems? One is that the database is
more work than the interface; the job of managing large quantities of
data, even from only one publisher in only one subject area, should
not be underestimated. In particular, data which involves more than flat
ASCII is tricky. There is inadequate standardization of special character
sets, procedures for subscripting/superscripting, printing equations, and
so on; yet if this is not done reasonably well the users will not be
able to read the result comfortably. Other lessons from data preparation
are that we should have bought enough magnetic disk storage at the start
of the project, and that one must scan gigabytes, not just a few
articles, to find all the special cases for the format conversion software.
Another important lesson is the value of pictures to the users.
[Ferguson 1992].
They
like looking at them, and in fact we prepared at one point a joking
interface (Figure 8) in which articles were represented by merely
a list of authors and small size images of the pictures, which we called
the ``comic book'' version.
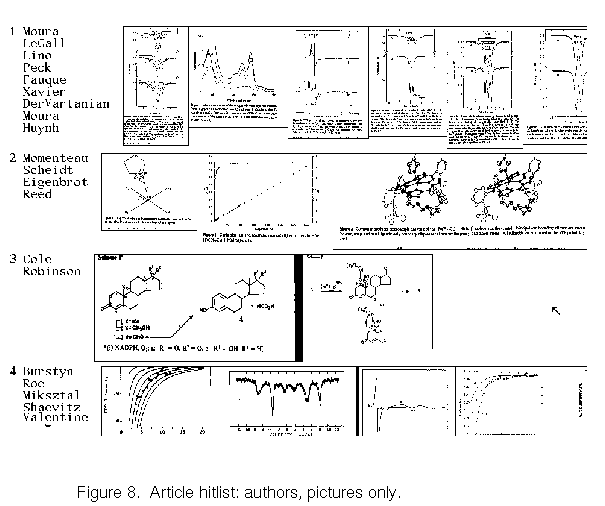
Anything that can be done to make the
pictures easier to view would be helpful.
We have also looked at
classifying the pictures directly rather than accessing them through
the articles, so far without success. The users frequently look
first and mostly at the pictures, though, so interfaces based on them
will be more successful.
Similarly, the users are very interested in browsing. The search metaphor
which dominates the retrieval field is not the only way to
look at a digital library, and not even the most important. Further work
in this area should emphasize catering to people who don't know what they
want until they see it.
Acknowledgements.
The CORE project thanks SONY of America, Digital Equipment Corporation,
Springer-Verlag, and Sun Microsystems for their contributions to the project.
This research was conducted using the resources of the Cornell Theory
Center, which receives major funding from the National Science Foundation
(NSF) and New York State. Additional funding comes from the Advanced
Research Projects Agency (ARPA), the National Institutes of Health (NIH),
IBM Corporation, and other members of the center's Corporate Research
Institute.
[Baird 1987].
Henry S. Baird;
"The Skew Angle of Printed Documents,"
Proceedings SPSE 40th Conf. on Hybrid Imaging Systems pp. 21-24, Rochester, NY, (May 1987).
[Birmingham 1994].
W. P. Birmingham, K. M. Drabenstott, C. O. Frost, A. J. Warner, and K. Willis;
"The University of Michigan Digital Library: This is Not Your Father's Library,"
Digital Libraries '94 Proceedings pp. 53-60, San Antonio, TX (June 19-21, 1994).
[Coombs 1987].
James H. Coombs, Allen H. Renear, and Steven J. DeRose;
"Markup systems and the future of scholarly text processing,"
CACM 30 (11) pp. 933-947 (1987).
[Egan 1989].
D. E. Egan, J. R. Remde, T. K. Landauer, C. C. Lochbaum, and L. M. Gomez;
"Behavioral Evaluation and Analysis Of a Hypertext Browser,"
Proc. CHI '89, Human Factors in Computing Systems pp. 205-210 (1989).
[Egan 1991].
D. E. Egan, M. E. Lesk, R. D. Ketchum, C. C. Lochbaum, J. R. Remde, M. Littman, and T. K. Landauer;
"Hypertext for the electronic library? CORE sample results,"
Proc. Hypertext '91, San Antonio (Dec. 1991).
[Ferguson 1992].
Eugene Ferguson Engineering and the Mind's Eye
MIT Press
(1992).
[Fletcher 1987].
L. A. Fletcher, and R. Kasturi;
"Segmentation of Binary Images into Text Strings and Graphics,"
Proc. SPIE Conf. on Applications of Artificial Intelligence V vol 786 pp. 533-540 (1987).
[Hoffman 1993].
M. M. Hoffman, L. O'Gorman, G. A. Story, J. Q. Arnold, and N. H. Macdonald;
"The RightPages Service: an image-based electronic library,"
J. Amer. Soc. for Inf. Science 44 pp. 446-452 (1993).
[Kibbey 1989].
Mark Kibbey, and N. H. Evans;
"The network is the library,"
EDUCOM Review 24 (3) pp. 15-20 (1989).
[Kirstein 1995]
Peter Kirstein and Goli Montasser-Kohsari;
"The C-ODA project; experiences and tools,"
Computer Journal, 38, no. 8, pp. 670-690 (1995).
[Kling 1994].
R. Kling, and M. Elliot;
"Digital Library Design for Organizational Usability,"
Digital Libraries '94 Proceedings pp. 146-155, San Antonio, TX (June 19-21, 1994).
[Love 1986].
R. A. Love;
"Chemical Journals Online (CJO)\-the new full-text database through STN International,"
Proc. Online '86 pp. 149-151 (1986).
[Lynch 1989].
Clifford A. Lynch;
"From telecommunications to networking: the MELVYL online union catalog and the development of intercampus networks at the University of California,"
Library Hi Tech 7 (2) pp. 61-83 (1989).
[McKnight 1993].
C. McKnight;
"Electronic journals\-past, present. . .and future?,"
ASLIB Proc. 45 pp. 7-10 (1993).
[Miksa 1994].
Francis L. Miksa, and Philip Doty;
"Intellectual Realities and the Digital Library,"
Digital Libraries '94 Proceedings pp. 1-5, San Antonio, TX (June 19-21, 1994).
[Ousterhout 1994].
John Ousterhout Tcl and the Tk tooklit
Addison-Wesley
(1994).
[Publishers 1987].
Association of American Publishers Standard for electronic manuscript preparation and markup, version 2.0.
AAP
(August 1987).
[Schatz 1994].
Bruce Schatz, Ann Bishop, William Mischo, and Joseph Hardin;
"Digital Library Infrastructure for a University Engineering Community,"
Digital Libraries '94 Proceedings pp. 21-24, San Antonio, TX (June 19-21, 1994).
[Srihari 1994].
S. N. Srihari, S. W. Lam, J. J. Hull, R. K. Srihari, and V. Govindaraju;
"Intelligent Data Retrieval from Raster Images of Documents,"
Digital Libraries '94 Proceedings pp. 34-40, San Antonio, TX (June 19-21, 1994).
[Stern 1990].
Barrie T. Stern;
"ADONIS-a vision of the future,"
pages 23-33 in Interlending and Document Supply, eds. G. P. Cornish and A. Gallico, British Library, (1990).
[Wang 1989].
Dacheng Wang, and S. N. Srihari;
"Classification of newspaper image blocks using texture analysis,"
Computer Vision, Graphics, and Image Processing 47 pp. 327-352 (1989).